








Методичні рекомендації щодо самостійної роботи з курсу Організація та проектування баз даних
« Назад
Методичні рекомендації щодо самостійної роботи з курсу Організація та проектування баз данихна тему: Основи роботи з базами даних 2013 р. ЗМІСТВСТУП... 3 1. Поняття про бази даних та системи управління базами даних.. 5 2. Моделі баз даних.. 12 3. Реляційні бази даних.. 17 4. Нормалізація баз даних.. 19 5. Поняття про ключі 30 6. Зв’язок між таблицями.. 31 7. Методи і способи доступу до даних.. 34 8. Робота із SQL Server. 35 9. Опис мови SQL.. 38 10. Типи даних у SQL.. 41 11. Визначення даних засобами SQL.. 43 12. Відбір даних із таблиць засобами SQL.. 53 13. Створення та використання таблиць бази даних засобами SQL Server Enterprise Manager. 71 14. Проектування реляційної бази даних.. 79 Список літератури.. 98
|
|
Співробітник |
Телефон |
|
Дацько П. Л. |
123 |
|
Ковальчук А. Ф. |
123 |
|
Криворучко О. Р |
456 |
|
Мигаль В. К. |
789 |
|
Шевченко Г. С. |
123 |
Три співробітники мають однаковий номер телефону 123, що може бути наприклад, коли вони працюють в одній кімнаті. У такий спосіб номер телефону в таблиці дублюється, однак для кожного співробітника цей номер є унікальним. У разі видалення одного з дубльованих значень номера телефону (видалення відповідної рядка таблиці) буде втрачена інформація про прізвище співробітника – Дацька П. Л., Ковальчук А. Ф. чи Шевченко Г. С., що є аномалією видалення.
У разі зміни номера телефону в кімнаті його слід змінити для всіх співробітників, що в ній працюють. Якщо для котрогось із співробітників цього не зробити, наприклад, для Ковальчук А. Ф., то виникає невідповідність даних, зв’язана з аномалією поновлення.
Аномалія введення полягає в тому, що в разі введення в таблицю нового рядка для його полів можуть бути введені недопустимі значення. Наприклад, значення не входить у заданий діапазон або не задане значення поля, яке обов’язково має бути заповнене (не може бути порожнім).
Тепер наведемо приклад надлишкового дублювання даних. Список телефонів доповнено номерами кімнат, у яких працюють співробітники (табл. 4.2). При цьому номер телефону зазначений тільки для одного зі співробітників – у прикладі для Дацька П. Л., що стоїть у списку першим. Замість номерів телефонів інших співробітників цієї кімнати поставлено прочерк. На практиці кодування прочерку залежить від особливостей конкретної таблиці, наприклад, можна позначати прочерк значенням Null.
Таблиця 4.2
Приклад надлишкового дублювання даних
|
Співробітник |
Кімната |
Телефон |
|
Дацько П. Л. |
17 |
123 |
|
Ковальчук А. Ф. |
17 |
- |
|
Криворучко О. Р |
22 |
456 |
|
Мигаль В. К. |
8 |
789 |
|
Шевченко Г. С. |
17 |
- |
Однак за такої побудови таблиці в нас з’являються проблеми:
- при зчитуванні номера телефону співробітника виникає необхідність пошуку цього номера в іншому рядку таблиці (за номером кімнати);
- при запам’ятовуванні таблиці для кожного рядка виділяється однакова пам’ять незалежно від наявності чи відсутності прочерків;
- при видаленні рядка з даними співробітника, проти якого зазначено номер телефону кімнати, буде втрачено інформацію про номер телефону для всіх співробітників цієї кімнати.
Якщо замість прочерків указати номер телефону, то надлишкове дублювання все одно залишається. Його можна позбутися, наприклад, розбивши таблицю на дві нові (табл. 4.3а і 4.3б). Розбивка – це процес поділу таблиці на кілька таблиць з метою підтримки цілісності даних, тобто усунення надмірності даних і аномалій. Таблиці 4.3а і 4.3б зв’язані між собою за номером кімнати. Для отримання інформації про номер телефону співробітника з першої таблиці за прізвищем співробітника потрібно вибрати номер його кімнати, після чого з другої таблиці за номером кімнати зчитується номер телефону.
Таблиця 4.3а
Список співробітників і номерів кімнат
|
Співробітник |
Кімната |
|
Дацько П. Л. |
17 |
|
Ковальчук А. Ф. |
17 |
|
Криворучко О. Р |
22 |
|
Мигаль В. К. |
8 |
|
Шевченко Г. С. |
17 |
Таблиця 4.3б
Список номерів кімнат, номерів кімнат і телефонів
|
Кімната |
Телефон |
|
17 |
123 |
|
8 |
789 |
|
22 |
456 |
Розглянутий поділ таблиці на дві є прикладом нормалізації відношень. При цьому надмірність даних зменшилася, однак одночасно зменшився час доступу до них. Для одержання номера телефону співробітника тепер потрібно працювати з двома таблицями, а не з однією, як у попередньому прикладі.
Для співробітників вказується номер кімнати, що приводить до ненадлишкового дублювання даних. Як було зазначено вище, таке дублювання є прийнятним для бази даних.
Приведення до нормальних форм. Процес проектування бази даних із використанням методу нормальних форм є ітераційним (покроковим) і полягає в послідовному перекладі за певними правилами відношень із першої нормальної форми в нормальні форми вищого порядку. Кожна наступна нормальна форма обмежує певний тип функціональних залежностей, усуває відповідні аномалії під час виконання операцій над відношеннями бази даних і зберігає властивості попередніх нормальних форм.
Виділяють таку послідовність нормальних форм:
- перша нормальна форма;
- друга нормальна форма;
- третя нормальна форма;
- посилена третя нормальна форма, чи нормальна форма Бойса – Кодда;
- четверта нормальна форма;
- п’ята нормальна форма.
Проектування починається з визначення всіх об’єктів, інформація про які має міститися в базі даних, і виділення атрибутів (характеристик) цих об’єктів. Атрибути всіх об’єктів зводять в одну таблицю, що є вихідною. Потім цю таблицю послідовно приводять до нормальних форм відповідно до вимог. На практиці зазвичай використовують три перші нормальні форми.
Для прикладу спроектуємо базу даних для збереження інформації про футбольний чемпіонат країни. У базі даних буде зберігатися інформація про дату матчу, про команди і забиті голи. Спочатку об’єднаємо всі дані в одну вихідну таблицю, яка має таку структуру (поля):
- дата матчу;
- команда господарів;
- команда гостей;
- гравець;
- ознака команди;
- час.
У даних про команду (господарі й гості) вкажемо її назву, місто і прізвище тренера, що однозначно ідентифікує будь-яку команду. Для гравця, який забив гол, будемо вказувати прізвище, а для позначення його належності до тієї чи іншої команди використовуємо ознаку, наприклад, н – для команди господарів, а м – для команди гостей. Час забиття гола представляємо Х хвилин, що пройшли з початку матчу.
Наведена таблиця має відносно просту структуру. У структурі таблиці зазначені тільки назви полів, оскільки тип і розмірність полів на даному етапі великого значення не мають.
Цю таблицю можна розглядати як однотабличну базу даних. Її головним недоліком є значна надмірність даних. Для кожного гравця, що забив гол, указані дата матчу й інформація про команди господарів і гостей. Дублювання даних може призвести до аномалій, а також до істотного збільшення розміру бази.
Перша нормальна форма. Наведемо вихідну таблицю до першої нормальної форми, для якої обов’язковими є такі умови:
- поля містять неподільну інформацію;
- у таблиці немає повторення груп полів.
У другому і третьому полях вихідної таблиці міститься інформація про назву команди, місто і тренера. Це суперечить першій вимозі – інформація про команду, місто і тренера є подільною. Ця інформація може і має бути розділена на три окремих поля – назва команди, місто, тренер.
Згідно з другою вимогою в таблиці не має бути полів, які повторюються, тобто групи, що містять однакові функціональні значення. У вихідній таблиці таких груп немає, тому другу вимогу вона задовольняє. Може здатися, що групами полів, які повторюються, є поля з інформацією про команди господарів і гостей. Незважаючи на те, що склад і значення названих полів цілком збігаються, ці поля мають різне функціональне призначення і не вважаються повторюваними.
Прикладом таблиці, яка має групи полів, що повторюються, може служити табл. 4.4 із результатами складання студентами екзаменаційної сесії. У цій таблиці для оцінок слід створити стільки полів, скільки може бути екзаменів із різних предметів. У зв’язку з тим, що студент складає не всі іспити (для них проставлено прочерки), розмір записів і самої таблиці невиправдано збільшується. Крім того, значні труднощі створює зміна складу предметів під час екзаменаційної сесії. Якщо організувати перейменування предмета досить просто, то його видалення чи додавання вимагає зміни структури таблиці. Структуру таблиці зазвичай визначають під час проектування бази даних і задають під час створення таблиці, тому реструктуризацію таблиці для вирішення цієї задачі не можна назвати зручним варіантом.
Таблиця 4.4
Результати складання екзаменаційної сесії
|
Студент |
Математика |
Інформатика |
Фізика |
Історія |
Англійська мова |
|
Кравченко Р. О. |
4 |
4 |
4 |
- |
4 |
|
Кривоніс В. К. |
4 |
3 |
3 |
- |
5 |
|
Шевченко Д. Г. |
5 |
5 |
- |
5 |
- |
|
Яремчук П. С. |
- |
- |
- |
3 |
3 |
Друга і третя нормальні форми стосуються відношень між ключовими і неключовими полями.
Друга нормальна форма. До другої нормальної форми є такі вимоги:
- таблиця має задовольняти вимоги першої нормальної форми;
- будь-яке неключове поле має однозначно ідентифікуватися ключовими полями.
Записи таблиці, приведеної до першої нормальної форми, не є унікальними і містять дубльовані дані. Так, якщо за одну хвилину футболіст забив кілька голів, то таблиця буде містити однакові записи. Щоб забезпечити унікальність записів, уведемо в таблицю поле ключа – код матчу. При цьому значення ключа буде однозначно визначати кожен запис таблиці.
Тоді структура таблиці буде такою:
- код матчу (унікальний ключ);
- дата матчу;
- назва команди господарів;
- місто команди;
- прізвище тренера команди господарів;
- назва команди гостей;
- місто команди гостей;
- прізвище тренера команди гостей;
- гравець;
- ознака команди;
- час.
Записи цієї таблиці мають значне надлишкове дублювання даних, тому що дата матчу, а також інформація про команди будуть вказані для кожного гола. Тому розіб’ємо таблицю на дві таблиці, одна з яких міститиме дані про матчі, а друга – про голи, забиті в кожному конкретному матчі. Структури цих таблиць будуть такими.
Поля таблиці матчів:
- код матчу (унікальний ключ);
- дата матчу;
- назва команди господарів;
- місто команди господарів;
- прізвище тренера команди господарів;
- назва команди гостей;
- місто команди гостей;
- прізвище тренера команди гостей.
Поля таблиці голів:
- код гола (унікальний ключ);
- код матчу;
- гравець;
- ознака команди;
- час.
Таблиці зв’язані за полем Код матчу, яке для таблиці матчу має унікальне значення. Щоб забезпечити унікальність записів таблиці голів, у неї введено ключове поле Код гола.
Третя нормальна форма. Вимогами третьої нормальної форми є такі:
- таблиця має задовольняти вимоги другої нормальної форми;
- жодне з неключових полів не має однозначно ідентифікуватися значенням другого неключового поля (полів).
Приведення таблиці до третьої нормальної форми припускає виділення в окрему таблицю (таблиці) тих полів, які не залежать від ключа. У таблиці матчів такими є поля з прізвищами тренерів команд, які однозначно визначаються значеннями назви і міста команди. Передбачається, що протягом сезону тренер у команді не міняється, що на практиці часто не виконується, але не змінює суті питання. Розіб’ємо таблицю матчів на дві таблиці: одну з даними про матчі і другу – з даними про команди. Їхню структуру наведено нижче:
Таблиця матчів:
- код матчу (унікальний ключ);
- дата матчу;
- код команди господарів;
- код команди гостей.
Таблиця команд:
- код команди (унікальний ключ);
- назва команди;
- місто;
- прізвище тренера.
Інформація про команду зберігається в символьних полях, які мають досить великий розмір – тут приблизно 60 символів. На практиці про кожну команду потрібно запам’ятовувати більше даних, аніж просто її назва, місто прописки і прізвище тренера, що зумовлює значний обсяг інформації. Тому для зменшення розміру записів таблиці матчів не тільки прізвище тренера, а й уся докладна інформація про команди винесена в таблицю команд. Замість цього команди господарів і гостей у таблиці матчів ідентифікуються кодом команди, який є унікальним ключовим значенням у таблиці команд.
Після приведення до третьої нормальної форми база даних з інформацією про футбольний чемпіонат країни буде мати структуру, показану на рис. 4.1, де, крім опису таблиць, позначені також і зв’язки між ними.

Рис. 4.1 - Структура бази даних «Чемпіонат із футболу»
Відповідність вимогам нормалізованих форм не завжди є обов’язковою. З ростом кількості таблиць структура бази даних ускладнюється і зростає час доступу до даних. Для спрощення структури бази даних можна допустити часткове дублювання даних, не допускаючи, однак, порушення їхньої цілісності і зберігаючи їхню несуперечність.
У розглянутій базі даних це стосується, наприклад, інформації про рахунок матчу. Щоб виключити дублювання даних, для нього не відведено окремого поля. Довідатися рахунок матчу можна за допомогою запитів до бази даних, які б підбивали кількість м’ячів, забитих у зазначеному матчі господарями і гістьми.
5. Поняття про ключі
У правильно побудованій реляційній базі даних у кожній таблиці є один чи кілька стовпців, значення яких у всіх рядках різні. Цей стовпець називається первинним ключем таблиці. Простий ключ складається з одного поля, а складений – із кількох полів. Поля, за якими побудовано ключ, називаються ключовими. У таблиці може бути визначений тільки один ключ. Ключ забезпечує:
- однозначну ідентифікацію записів таблиці;
- застереження повторення значень ключа;
- прискорення виконання запитів до бази даних;
- установлення зв’язку між окремими таблицями бази даних.
Ключ називають первинним ключем, або первинним (головним) індексом. Інформація про ключ може зберігатися в окремому файлі або разом із даними таблиці.
Таблиці різних форматів мають свої особливості побудови ключів. Разом з тим є й загальні правила, суть яких полягає ось у чому:
- ключ має бути унікальним. У кожному ключі значення окремих полів (але не всіх одночасно) можуть повторюватися;
- ключ має бути достатнім і ненадлишковим, тобто не містити поля, які можна знищити без порушення унікальності ключа;
- у склад ключа не можуть входити поля деяких типів, наприклад, графічне поле або поле-коментар.
6. Зв’язок між таблицями
База даних може складатися з однієї таблиці. Однак зазвичай реляційні бази даних складаються із взаємозв’язаних таблиць. Організація зв’язку між таблицями називається зв’язуванням, або з’єднанням, таблиць.
Зв’язок між таблицями можна встановлювати як під час створення бази даних, так і під час використання, засобами, які надає СУБД. Зв’язувати можна дві або кілька таблиць. У реляційній базі, крім зв’язаних, можуть бути і окремі таблиці, не з’єднані з жодною іншою таблицею.
Для зв’язування таблиць використовуються ключові поля (іноді використовується термін «поля, що збігаються»). У головній таблиці для зв’язування береться поле – первинний ключ. У підпорядкованій таблиці для зв’язку з головною таблицею береться поле, яке називається зовнішнім ключем. Значення полів головної і підпорядкованої таблиці мають збігатися.
Зв’язок між таблицями визначає відношення підпорядкованості, за якого одна таблиця є головною, а друга – підпорядкованою. Сам зв’язок називають зв’язком «головний-підлеглий», «батьківський-дочірній». Є кілька видів зв’язку:
- відношення «один-до-одного»;
- відношення «один-до-багатьох»;
- відношення «багато-до-одного»;
- відношення «багато-до-багатьох».
Відношення «один-до-одного» означає, що одному запису в головній таблиці відповідає один запис у підпорядкованій таблиці. При цьому можливі два варіанти:
- для кожного запису головної таблиці є запис у підпорядкованій таблиці;
- у підпорядкованій таблиці може не бути записів, відповідних до записів головної таблиці.
Відношення «один-до-багатьох» означає, що одному запису головної таблиці може відповідати кілька записів підпорядкованої таблиці, в окремому випадку жодного. Цей вид відношення трапляється найчастіше.
Відношення «багато-до-одного» відрізняється від відношення «один-до-багатьох» тільки напрямком. Якщо на відношення «один-до-багатьох» подивитися з боку підпорядкованої таблиці, а не головної, то воно перетворюється у відношення «багато-до-одного».
Відношення «багато-до-багатьох» має місце, коли одному запису головної таблиці може відповідати кілька записів підпорядкованої таблиці і одночасно одному запису підпорядкованої таблиці – кілька записів головної таблиці. Таке відношення можливе, наприклад, щодо планування занять у навчальному закладі і встановлюється між таблицями, в яких зберігається інформація про номери аудиторій і номери навчальних груп. Оскільки навчальна група може мати заняття в різних аудиторіях, то одному запису про навчальну групу (перша таблиця) може відповідати кілька записів аудиторій, у яких ця група навчається. У той же час в одній аудиторії можуть мати лекції різні навчальні групи (навіть одночасно), тому одному запису про аудиторії може відповідати кілька записів про навчальні групи (друга таблиця).
На практиці відношення «багато-до-багатьох» використовується досить рідко. Для цього типу відношення поняття головної і підпорядкованої таблиці позбавлені змісту.
Серед розглянутих відношень найбільш загальним є відношення «один-до-багатьох».
Робота із зв’язаними таблицями має такі особливості:
- у разі зміни (редагування) ключового поля може порушитися зв’язок між записами двох таблиць. Тому під час редагування поля зв’язку запису головної таблиці потрібно відповідно змінювати і значення поля зв’язку всіх підпорядкованих таблиць;
- у разі знищення запису головної таблиці потрібно знищити і відповідні їй записи в підпорядкованій таблиці (каскадне знищення);
- у разі додавання запису в підпорядковану таблицю значення її поля зв’язку має бути встановлене рівним значенню поля зв’язку головної таблиці.
7. Методи і способи доступу до даних
Методи доступу до даних таблиці поділяються на:
- послідовні;
- прямі;
- індексно-послідовні.
За послідовного методу доступу виконується послідовний перегляд усіх записів таблиці і пошук потрібних із них. Цей метод доступу є найменш ефективним і призводить до значних затрат часу на пошук, які прямо пропорційні розміру таблиці (кількості її записів). Тому його можна використовувати для відносно невеликих таблиць.
За прямого методу доступу потрібний запис вибирається з таблиці на основі ключа або індексу. При цьому перегляду інших записів не виконується. Нагадаємо, що значення ключів та індексів розташовуються в певному порядку і містять посилання, які вказують на розміщення відповідного запису в таблиці. Під час пошуку запису виконується не послідовний перегляд усієї таблиці, а безпосередній доступ до запису на основі посилання.
Індексно-послідовний метод доступу включає в себе елементи послідовного і прямого методів доступу та використовується для пошуку групи записів. Цей метод реалізується тільки за наявності індексу, збудованого за полями, значення яких потрібно знайти. Суть його полягає в тому, що знаходиться індекс першого запису, який задовольняє задану вимогу, і відповідний запис обирається з таблиці на основі посилання. Це є прямим доступом до даних. Після обробки першого знайденого запису здійснюється перехід до наступного значення індексу, і з таблиці обирається запис, відповідно до значення цього індексу. Таким чином поступово перебираються індекси всіх записів, які задовольняють задані умови, що є послідовним доступом.
8. Робота із SQL Server
Усі мови маніпулювання даними, створені до появи реляційних баз даних і розроблені для багатьох систем управління базами даних персональних комп’ютерів, були зорієнтовані на операції з даними, поданими у формі логічних записів файлів. Це вимагало від користувачів детального знання організації збереження даних для визначення не тільки того, які дані потрібні, а й того, де вони розміщені і як їх одержати.
Непроцедурна мова SQL (Structured Query Language – структурована мова запитів) зорієнтована на операції з даними, поданими у формі логічно взаємозалежних сукупностей таблиць. Особливість операцій цієї мови полягає в тому, що вони зорієнтовані здебільшого на кінцевий результат обробки даних, аніж на процедуру цієї обробки. SQL сама визначає, де містяться дані, які індекси і навіть найбільш ефективні послідовності операцій варто використовувати для їх одержання: не треба вказувати ці деталі в запиті до бази даних.
На початку 80-х років минулого століття SQL «перемогла» інші мови запитів і стала фактичним стандартом таких мов для професійних реляційних СУБД. У 1987 році вона стала міжнародним стандартом мови баз даних, її почали впроваджувати в усі поширені СУБД персональних комп’ютерів.
Безупинний ріст швидкодії, а також зниження енергоспоживання, розмірів і вартості комп’ютерів привели до різкого розширення можливих ринків їх збуту, кола користувачів, розмаїтості типів і цін. Природно, що розширився попит на різноманітне програмне забезпечення.
Борючись за покупця, фірми, які розробляють програмне забезпечення, почали випускати на ринок усе більш і більш інтелектуальні і, відповідно, об’ємні програмні комплекси. Придбавши такі комплекси, багато організацій і окремих користувачів часто не могли розмістити їх на власних комп’ютерах, однак не хотіли і відмовлятися від нового сервісу. Для обміну інформацією та її узагальнення були створені комп’ютерні мережі, де узагальнені програми і дані почали розміщувати на спеціальних обслуговувальних пристроях – файлових серверах.
СУБД, які працюють із файловими серверами, дозволяють багатьом користувачам різних комп’ютерів (іноді розташованих досить далеко один від одного) одержувати доступ до тих самих баз даних. При цьому спрощується розробка різних автоматизованих систем керування організаціями, навчальних комплексів, інформаційних та інших систем, де безліч співробітників (учнів) повинні використовувати загальні дані й обмінюватися даними, створеними у процесі роботи (навчання). Однак за такої ідеології вся обробка запитів із програм або з робочих станцій користувачів виконується на тих же комп’ютерах користувачів. Тому для реалізації навіть простого запиту ЕОМ часто має зчитувати з файлового сервера і (чи) записувати на сервер цілі файли, що веде до конфліктних ситуацій і перевантаження мережі.
Для усунення зазначених і деяких інших недоліків була запропонована технологія «клієнт-сервер», за якою запити робочих станцій (клієнт) обробляються на спеціальних серверах баз даних (сервер), а на робочі станції повертаються лише результати обробки запиту. При цьому, природно, потрібна єдина мова спілкування із сервером і такою мовою обрано SQL. Тому всі сучасні версії професійних реляційних СУБД (DB2, Oracle, Іnformіx, Sybase, Progress, Rdb) і навіть нереляційних СУБД (наприклад, Adabas) використовують технологію «клієнт-сервер» і мову SQL.
Реалізація в SQL концепції операцій, зорієнтованих на табличне представлення даних, дозволило створити компактну мову з невеликим набором операторів. SQL можна використовувати як для виконання запитів, так і для побудови прикладних програм. Можливості мови SQL:
- визначення даних (створення баз даних, а також створення і видалення таблиць та індексів);
- запити на вибір даних (оператор SELECT);
- модифікація даних (додавання, видалення і зміна даних);
- керування даними (надання і скасування привілеїв на доступ до даних, керування трансакціями й інші).
Крім того, вона дає можливість виконувати:
- арифметичні обчислення (включаючи різноманітні функціональні перетворення), обробку текстових рядків і виконання операцій порівняння значень арифметичних виразів і текстів;
- упорядкування рядків і (чи) стовпців при виведенні вмісту таблиць на друк або на екран дисплея;
- створення виглядів (віртуальних таблиць), що дозволяють користувачам мати свій погляд на дані без збільшення їхнього обсягу в базі даних;
- запам’ятовування виведеного за запитом вмісту таблиці, кількох таблиць або вигляду в іншій таблиці (реляційна операція присвоювання).
- агрегування даних: групування даних і застосування до цих груп таких операцій, як середнє арифметичне, сума, максимум, мінімум, кількість елементів тощо.
Центральним компонентом SQL Server є реляційна база даних і її структура. У середовищі SQL Server можна створити до 32 766 баз даних. У кожній базі даних може бути до 2 млрд таблиць, у кожній таблиці – до 1 024 стовпців. Щодо кількості рядків таблиці, то обмежень нема. Але реальне обмеження – це ємність пристрою, на якому зберігаються таблиці.
9. Опис мови SQL
SQL – стандартна мова запитів для роботи з реляційною базою даних. Вона з’явилася після реляційної алгебри, і її прототип був розроблений у кінці 70-х років минулого століття в компанії IBM Research. Мова SQL була реалізована в першому прототипі реляційної СУБД фірми IBM System R. Надалі цю мову застосовували в багатьох комерційних СУБД, і через масове поширення вона поступово стала стандартом для мов маніпулювання даними в реляційних СУБД.
Мову SQL не можна повністю віднести до традиційних мов програмування. Вона не має традиційних операторів, які керують ходом виконання програми, операторів опису типів і багато іншого. Вона містить тільки набір стандартних операторів доступу до даних, які зберігаються в базі даних. Оператори SQL вбудовуються в базову мову програмування, якою може бути будь-яка стандартна мова типу С++, PL, COBOL і т. д. Крім цього, оператори SQL можуть виконуватися безпосередньо в інтерактивному режимі. Це забезпечує користувачам негайний доступ до даних. За допомогою SQL користувач може в інтерактивному режимі одержати відповіді на найскладніші запити в лічені хвилини чи секунди, тоді як програмістові потрібні були б дні чи тижні, щоб написати для користувача відповідну програму. Оператори SQL використовуються як для інтерактивного, так і для програмного доступу, тому частини програм, що містять звертання до бази даних, можна спочатку тестувати в інтерактивному режимі, а потім вбудовувати в програму.
Засоби SQL використовуються для виконання операцій із локальними і віддаленими базами даних. Головною перевагою реляційного способу доступу до даних є незначне завантаження мережі, оскільки передаються тільки запити і результати їх виконання.
Мова SQL зорієнтована на виконання дій із таблицями бази даних і даними в цих таблицях. На відміну від процедурних мов програмування, у ній немає операторів управління обчислювальним процесом (циклів, переходів, розгалуження) і засобів уведення-виведення. Складену мовою SQL програму називають SQL-запитом.
У мові SQL можна виділити такі головні підмножини операторів.
1. Оператори визначення даних DDL (Data Definition Language):
- CREATE TABLE – створює нову таблицю в базі даних;
- DROP TABLE – видаляє таблицю з бази даних;
- ALTER TABLE – змінює структуру таблиці;
- CREATE VIEW – створює віртуальну таблицю, яка відповідає певному SQL-запиту;
- ALTER VIEW – змінює створену віртуальну таблицю;
- DROP VIEW – видаляє створену віртуальну таблицю;
- CREATE INDEX – створює індекс для певної таблиці для забезпечення швидкого доступу за атрибутами, що входять в індекс;
- DROP INDEX – видаляє індекс.
2. Оператори маніпулювання даними DML (Data Manipulation Language):
- DELETE – видаляє рядки;
- INSERT – вставляє рядок;
- UPDATE – поновлює значення рядка.
3. Оператор управління доступом до даних – мова запитів DQL (Data Query Language):
- SELECT – вибирає рядки. Цей оператор заміняє всі оператори реляційної алгебри і дозволяє сформувати результатне відношення, відповідне до запиту.
4. Оператори управління трансакціями:
- СOMMIT – завершує трансакцію;
- ROLLBACK – скасовує зміни, здійснені в ході виконання трансакції;
- SAVEPOINT – зберігає проміжний стан бази даних у ході виконання трансакції.
5. Оператори адміністрування даних:
- CREATE DATABASE – створює базу даних;
- ALTER DATABASE – змінює базу даних;
- ALTER DBAREA – змінює область зберігання бази даних;
- ALTER PASSWORD – змінює пароль для всієї бази даних;
- DROP DATABASE – видаляє базу даних;
- CREATE DBAREA – створює область зберігання і робить її доступною для розміщення даних.
Мова SQL надає для користування низку функцій, з яких найчастіше використовуються:
- AVG () – середнє значення стовпця;
- MAX () – максимальне значення стовпця;
- MIN () – мінімальне значення стовпця;
- SUM () – сума стовпця;
- COUNT () – кількість значень у стовпці;
- COUNT (*) – кількість нульових значень стовпця.
Для опису операторів мови використовують символи < > для позначення окремих елементів. Регістр літер не впливає на інтерпретацію операторів мови. Крапка з комою в кінці SQL-операторів необов’язкова. Елементи в списках, наприклад, імена полів і таблиць, мають бути розділені комами.
Імена таблиць і полів беруть у лапки. Якщо ім’я не містить пробілів та інших спеціальних символів, то лапок можна не вказувати.
У SQL-запиті допускаються коментарі, які пояснюють текст програми. Коментар обмежується символами /* і */.
10. Типи даних у SQL
Головну роль у створенні таблиці відіграє визначення типів даних для полів таблиці. SQL дозволяє визначити кілька типів даних, включаючи текстові, числові та двійкові. Можна також визначити власні типи даних для використання в таблицях.
Тип даних – це перша характеристика, яку потрібно визначити для поля в разі створення таблиці. Тип даних поля визначає тип інформації, яку можна зберігати в цьому полі. Щоб визначити тип даних, після імені поля потрібно вказати відповідне ключове слово. Тип даних для поля таблиці зберігається як постійна характеристика, змінити яку вже не можна.
Основні типи даних SQL наведено в табл. 10.1.
Таблиця 10.1
Основні типи даних
|
Тип даних |
Характеристика |
|
ІNTEGER |
ціле число (до 10 значущих цифр і знак) |
|
SMALLІNT |
«коротке ціле» (до 5 значущих цифр і знак) |
|
DECІMAL(p,q) |
десяткове число, що має p цифр (0 < p < 16) і знак; за допомогою q задається число цифр праворуч від десяткової крапки (q < p, якщо q = 0, то його можна опустити) |
|
FLOAT |
дійсне число з 15 значущими цифрами і цілочисельним порядком, який визначається типом СУБД |
|
CHAR (n) |
символьний рядок фіксованої довжини з n символів (0 < n < 256) |
|
VARCHAR (n) |
символьний рядок змінної довжини, що не перевищує n символів (n > 0 і різне в різних СУБД, але не менше ніж 4 096) |
|
DATE |
дата у форматі, визначеному спеціальною командою (за замовчуванням mm/dd/yy); поля дати можуть містити тільки реальні дати, що починаються за кілька тисячоліть до н. е. і обмежені 5–10 тисячоліттями н. е. |
|
TІME |
час у форматі, визначеному спеціальною командою (за замовчуванням hh.mm.ss) |
|
DATETІME |
комбінація дати і часу; |
|
MONEY |
гроші у форматі, який визначає символ грошової одиниці ($, руб....) і його розташування (суфікс або префікс), точність дробової частини та умова для показу грошового значення |
Поняття про атрибути.
Для поля можна визначити не лише тип даних, а й ще одну додаткову характеристику – NULL і NOT NULL. Якщо для поля таблиці визначено атрибут NULL, то це дозволяє під час уведення даних не вказувати значення цього поля. Якщо ж, навпаки, для стовпця визначено атрибут NOT NULL, то SQL Server не дозволить залишити це поле порожнім під час додавання запису. Таким чином, атрибути NULL і NOT NULL виконують функцію перевірки допустимості даних. За замовчуванням полю надається атрибут NOT NULL, який не дозволяє залишати в полі невизначені значення:
- Атрибут PRIMARY KEY установлює первинний (внутрішній) ключ.
- Атрибут FOREIGN KEY установлює вторинний (зовнішній) ключ.
- Атрибут UNIQUE застосовується для будь-якого поля з метою не дозволити вводити значення, які повторюються. Таке поле не може бути ключем чи складовою частиною ключа.
- Атрибут DEFAULT забезпечує автоматичне введення в поле повне значення.
- Атрибут CHECK накладає умови на введення даних.
11. Визначення даних засобами SQL
Визначення даних – це маніпулювання цілими таблицями. Сюди можна віднести:
- створення нової таблиці;
- видалення таблиці;
- зміна складу полів таблиці;
- створення і видалення індексу.
Ці дії виконують за допомогою підмножини операторів визначення даних мови SQL.
Створення і знищення таблиці. Для створення таблиці служить оператор, який має такий формат:
CREATE TABLE <Ім’я таблиці>
(<Ім’я поля> <Тип даних> [<атрибут>],
< Ім’я поля > <Тип даних> [<атрибут>])
Обов’язковими операндами є ім’я таблиці та ім’я, як мінімум, одного поля з відповідним типом даних. Зазначимо, що замість імені таблиці вказується ім’я головного файла таблиці.
Наприклад, треба створити базу даних працівників рекламного агентства. Ця база має містити дві таблиці. Таблиця «Штат рекламних агентів» містить таку інформацію про рекламних агентів:
- код працівника;
- прізвище, ім’я, по батькові;
- домашня адреса;
- телефон;
- дата народження;
- освіта;
- стаж роботи.
У другій таблиці «Обсяг операцій» має міститися інформація про операції, які здійснюють рекламні агенти:
- номер операції;
- код працівника;
- дата операції;
- сума операції;
- назва рекламодавця.
Команди створення цих таблиць наведено нижче.
- create table stat;
- (cod smallint not null;
- prizv char(20) not null;
- adressa char(20) null;
- tel char(10) null;
- data_nar smalldatetime not null;
- osvita char(20) null;
- stag int not null);
- create table obsag;
- (nom smallint not null;
- cod smallint not null;
- data smalldatetime not null;
- suma int not null;
- nazva char(20) null).
Якщо в таблиці «Обсяг операцій» треба вказати поля Кількість товару, Ціна товару і Сума операції, то слід використати розрахункове поле, яке в команді створення таблиці має назву suma і розраховується як добуток поля Кількість товару і поля Ціна товару:
- номер операції;
- код працівника;
- дата операції;
- кількість товару;
- ціна товару;
- сума операції;
- назва рекламодавця.
Відповідно поле в команді створення цієї таблиці буде таке:
- create table obsag
- (nom smallint not null,
- cod smallint not null,
- data smalldatetime not null,
- kilkist smallint not null,
- cina money not null,
- suma as kilkist * cina,
- nazva char(20) null)
Щоб переглянути структуру створеної таблиці, використовують процедуру SP_HELP <ім’я таблиці>, наприклад, sp_help stat. Результат виконання команди має такий вигляд:

Для знищення таблиці призначений оператор.
DROP TABLE <ім’я таблиці>, наприклад: drop table stat.
Зміна складу полів таблиці.
Зміна складу полів таблиці полягає в додаванні або знищенні полів і призводить до зміни структури таблиці. Зміна складу полів таблиці виконується таким оператором:
ALTER TABLE <ім’я таблиці>
ADD <ім’я поля> <тип даних>
ALTER TABLE <ім’я таблиці>
DROP COLUMN <ім’я поля>
Операнд ADD додає до таблиці нове поле, ім’я і тип якого задаються як і в операторі CREATE, а операнд DROP COLUMN знищує в таблиці поле із заданим іменем. Наприклад, додавання до таблиці stat поля number виконується таким оператором:
alter table stat
add number int
Коли за допомогою оператора ALTER TABLE до таблиці додається новий стовпець, то в нього автоматично поміщаються NULL-значення.
Знищення поля number із таблиці stat виконується за допомогою такого оператора:
alter table stat
drop column number
За допомогою оператора ALTER TABLE можна змінити тип даних полів таблиці, а також їхню ширину. Наприклад, оператор змінює тип поля tel на цілочисельний (int).
alter table stat
alter column tel int
Додавання первинних і вторинних ключів. Зв’язування таблиць.
Первинний ключ – це унікальне поле (або набір полів), яке визначає рядки таблиці бази даних. Первинні ключі забезпечують унікальність даних шляхом створення унікального індексу в таблиці, в якій вони розміщені. Вторинні ключі – це поля таблиці, які відповідають первинним ключам інших таблиць. Співвідношення між первинними і вторинними ключами визначають область допустимих значень для вторинного ключа. Цілісність області значень зовнішнього ключа є одним із способів забезпечення цілісності зв’язків між відповідними наборами полів. При визначенні вторинних ключів індекси в таблиці не створюються.
У SQL Server первинні і вторинні ключі можна додати трьома способами: використовуючи SQL Server Enterprise Manager, оператор ALTER TABLE … ADD CONSTRAINT або визначивши опцію PRIMARY/FOREIGN KEY в операторі CREATE TABLE.
У синтаксисі команди CREATE TABLE передбачена можливість додавання в розділі CONSTRAINT елементів PRIMARY KEY або FOREIGN KEY. Спрощений формат команди:
CREATE TABLE <Ім’я таблиці>
(<Ім’я поля> <Тип даних> CONSTRAINT …, …)
Наприклад, оператор для створення таблиці, коли не вказується ім’я первинного ключа (воно буде призначене сервером) виглядає так:
CREATE TABLE <Ім’я таблиці>
(<Ім’я поля> smallint PRIMARY KEY)
Якщо потрібно явно вказати ім’я первинного ключа при створенні таблиці, то команда має таку послідовність:
CREATE TABLE <Ім’я таблиці>
(<Ім’я поля> smallint CONSTRAINT pk_<Ім’я поля> PRIMARY KEY,)...)
Вторинний ключ таблиці_2, який посилається на таблицю_1, можна створити командою:
CREATE TABLE <Ім’я таблиці_2>
(<Ім’я поля_2> smallint FOREIGN KEY <Ім’я поля_2> REFERENCES <Ім’я таблиці_1>(<Ім’я поля_1>),...)
Цією командою встановлюється зв’язок між таблицею_1 і таблицею_2, причому ключові поля у двох таблицях повинні мати абсолютно однакові типи даних.
Тепер розглянемо оператори, які використовують для зміни таблиць із метою додавання первинних і вторинних ключів.
Для додавання первинного ключа без визначення його імені використовують оператор такого формату:
ALTER TABLE <Ім’я таблиці_1>
ADD PRIMARY KEY ( <Ім’я поля_1>)
Наприклад, таблиці «Штат рекламних агентів» і «Обсяг операцій» маємо зв’язати за полем Код працівника. При цьому поле Код працівника першої таблиці є первинним ключем, а поле Код працівника другої таблиці – вторинним ключем. Команда додавання до таблиці «Штат рекламних агентів» первинного ключа:
alter table stat
add primary key (cod)
Додавання вторинного ключа до таблиці_2, який посилається на таблицю_1, виконується командою:
ALTER TABLE <Ім’я таблиці_2>
ADD FOREIGN KEY (<Ім’я поля_2>) REFERENCES <Ім’я таблиці_1> (<Ім’я поля_1>)
Аналогічно до команди CREATE TABLE, цією командою встановлюється зв’язок між таблицею_1 і таблицею_2, причому ключові поля у двох таблицях повинні мати абсолютно однакові типи.
Наприклад, додавання вторинного ключа до таблиці «Обсяг операцій» і встановлення зв’язку з таблицею «Штат рекламних агентів» за полем Код працівника виконується командою:
alter table obsag
add foreign key (cod) references stat (cod)
Для відображення інформації про ключі в SQL Server використовують дві системні процедури. Основний спосіб відображення інформації про ключі полягає у використанні процедури SP_HELPCONSTRAINT, яка має такий формат:
SP_HELPCONSTRAINT <Ім’я таблиці>
Наприклад, sp_helpconstraint stat.
Результат виконання команди показано на рис. 11.1.
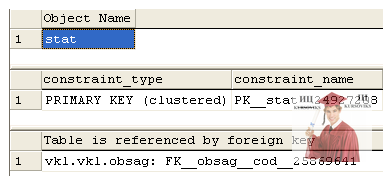
Рис. 11.1 - Інформація про ключі таблиці stat
Видалення первинних і вторинних ключів виконується командою:
ALTER TABLE <Ім’я таблиці>
DROP CONSTRAINT <Ім’я ключа>
Зазначимо, що не можна видалити первинний ключ, якщо він є вторинним ключем для інших таблиць. Спочатку потрібно видалити вторинні ключі.
Наприклад, команди для видалення зовнішнього і внутрішнього ключів:
alter table obsag
drop constraint FK__obsag__cod__239E4DCF
alter table stat
drop constraint PK__stat__22AA2996
Модифікація записів.
Модифікація записів полягає в редагуванні записів, у додаванні до набору даних нових записів або видаленні наявних записів.
Додавання записів здійснюється з допомогою оператора INSERТ, який дозволяє додати до таблиці один або кілька записів. У разі додавання одного запису оператор INSERТ має формат:
INSERТ INTO <Ім’я таблиці>
[(<Список полів>)]
VALUES (<Список значень>)
У результаті виконання цього оператора до таблиці, ім’я якої вказано після слова INTO, додається один запис. Для додавання запису заповнюються поля, перелічені в списку полів. Значення полів беруть із списку, розміщеного після слова VALUES. Списки полів і списки значень мають відповідати один одному за кількістю елементів і за типом елементів. При цьому порядок полів і значень може відрізнятися від порядку полів у таблиці.
Наприклад, таблицю «Штат рекламних агентів» треба наповнити даними, що наведені в табл. 11.1.
Таблиця 11.1
Штат рекламних агентів
|
Код працівника |
Прізвище, ім’я, |
Домашня адреса |
Телефон |
Дата народження |
Освіта |
Стаж роботи |
|
101 |
Шостак Т. Х. |
Львів |
772345 |
05/05/1968 |
вища |
10 |
|
102 |
Драч О. О. |
Львів |
456789 |
12/31/1970 |
середня |
7 |
|
103 |
Пилипів І. В. |
Стрий |
568905 |
08/25/1967 |
вища |
5 |
|
104 |
Леськів А. В. |
Київ |
2290706 |
03/13/1976 |
середня |
2 |
|
105 |
Дорош К. Ф. |
Київ |
2908745 |
07/23/1952 |
вища |
16 |
Таблиця «Обсяг операцій» має містити дані, які відображає табл. 11.2.
Таблиця 11.2
Обсяг операцій
|
Номер операції |
Код працівника |
Дата операції |
Сума операції |
Назва рекламодавця |
|
1 |
101 |
05/05/05 |
1200 |
Ельдорадо |
|
2 |
102 |
05/07/05 |
2300 |
Фокстрот |
|
3 |
102 |
05/11/05 |
3400 |
Маестро |
|
4 |
103 |
05/12/05 |
800 |
Корона |
|
5 |
101 |
05/12/05 |
1200 |
Фокстрот |
|
6 |
101 |
06/01/05 |
567 |
Корона |
|
7 |
104 |
06/11/05 |
789 |
Ельдорадо |
|
8 |
104 |
06/11/05 |
1567 |
Фокстрот |
|
9 |
105 |
06/25/05 |
2340 |
Ельдорадо |
Додавання першого запису до таблиці «Штат рекламних агентів» виконується командою:
insert into stat
(cod, prizv, adressa, tel, data_nar, osvita, stag)
values (101, ‘Шестак’, ‘Львів’, 772345, ‘05/05/1968’, ‘вища’, 10)
Аналогічно додають решту записів полів таблиці.
Списку полів в операторі INSERТ може не бути, тоді потрібно вказувати значення для всіх полів таблиці. Порядок і тип значень має відповідати порядку і типу полів таблиці.
Редагування записів – це зміна значень полів у групі записів. Редагування записів виконується оператором UPDATE такого формату:
UPDATE <Ім’я таблиці>
SET <Ім’я поля> = <Вираз>
[WHERE <Критерії відбору>]
Після виконання оператора UPDATE для всіх записів, що задовольняють критерії відбору, змінюються значення полів. <Ім’я поля> вказує поле, що редагується, всієї сукупності даних, а <Вираз> визначає значення, які будуть присвоєні цьому полю.
Наприклад,
update stat
set adressa= ‘Київ’, stag=10
У результаті виконання цієї команди значення поля adressa в усіх записах (рядках) таблиці змінюється на ‘Київ’, а поле stag – на 10.
За допомогою оператора UPDATE можна змінити кілька рядків, які задовольняють критерій, визначений у директиві WHERE. Наприклад,
update obsag
set suma = suma – 20
where nazva =‘Маестро’
Для рекламодавця ‘Маестро’ сума операції зменшується на 20 одиниць. Якщо забрати операнд WHERE, то зміняться значення поля suma в усіх записах таблиці. Наприклад,
update obsag
set suma = suma – 20
Видалення записів виконується оператором DELETE такого формату:
DELETE FROM <Ім’я таблиці>
[WHERE <Критерії відбору>]
У результаті виконання цього оператора з таблиці, ім’я якої вказано після слова FROM, видаляються всі записи, які задовольняють критерій відбору. Якщо критерію відбору не задано, то з таблиці буде видалено всі записи.
Наприклад,
delete from stat
where stag <10
З таблиці stat видаляються всі записи про працівників, стаж роботи яких менший ніж 10.
12. Відбір даних із таблиць засобами SQL
Відбір даних із таблиць полягає в одержанні з них полів і записів, які задовольняють певні умови. Результат виконання запиту, на основі якого відбираються записи, називають вибіркою. Дані можна вибирати з однієї або кількох таблиць за допомогою оператора SELECT. Він має такий формат:
SELECT [DISTINCT] {*| <Список полів>}
FROM <Список таблиць>
[WHERE <Умови відбору>]
[ORDER BY <Список полів для сортування>]
[GROUP BY <список полів для групування>]
[HAVING <умови групування>]
[UNION <вкладенний оператор SELECT>]
Тут SELECT – ключове слово, яке повідомляє СУБД, що ця команда – запит. Усі запити починаються цим словом.
У результатному наборі даних можуть дозволятися або не дозволятися записи, які повторюються (тобто мають однакові значення всіх полів). Цим режимом керує операнд DISTINCT. Якщо його немає, то в наборі даних дозволяються записи, які повторюються.
В оператор SELECT обов’язково включається: список полів і операнд FROM, інших операндів може не бути. Ключове слово FROM, після якого задаються імена таблиць, указує на джерело інформації для запиту. У списку таблиць має бути як мінімум одна таблиця.
Якщо в набір даних потрібно включити всі поля таблиці, то замість перерахованих імен полів указують символ «*». Якщо список містить поля кількох таблиць, то, щоб показати належність поля до таблиці, використовують складене ім’я, яке включає ім’я таблиці та ім’я поля, розділені крапкою: <ім’я таблиці>.<ім’я поля>.
Операнд WHERE задає умови (критерії) відбору, які мають задовольняти записи в результатному наборі даних. Вираз, який описує умову відбору, є логічним виразом. Його елементами можуть бути імена полів, операції порівняння, арифметичні і логічні операції, спеціальні функції LIKE, NULL, IN.
Операнд GROUP BY дозволяє виділяти групи записів у результатному наборі даних. Групою є записи з однаковими значеннями в полях, які перераховані після ключових слів GROUP BY.
Операнд HAVING діє сумісно з оператором GROUP BY і використовується для відбору записів усередині групи.
Операнд ORDER BY містить список полів, які визначають порядок сортування записів результатного набору даних. За замовчуванням, сортування відбувається в порядку зростання значень. Якщо треба посортувати за спаданням, то після імені цього поля вказується описувач DESС.
Оператори SELECT можуть мати складну структуру і бути вкладеними один в одного. Для об’єднання операторів використовується операнд UNION, в якому розміщається вкладений оператор SELECT, який називають підзапитом.
У синтаксичній конструкції оператора SELECT використовують такі позначення:
- зірочка (*) для позначення «усі» – використовується у звичайному для програмування змісті, тобто «усі випадки, що задовольняють умову»;
- квадратні дужки [] – означають, що конструкції, укладені в ці дужки, є необов’язковими (тобто можуть бути опущені);
- фігурні дужки {} – означають, що конструкції, укладені в ці дужки, слід розглядати як цілі синтаксичні одиниці, тобто вони дозволяють уточнити порядок розбору синтаксичних конструкцій, заміняючи звичайні дужки, які використовуються в синтаксисі SQL;
- трикрапка … – вказує на те, що синтаксична одиниця, зазначена перед нею, факультативно може повторюватися один чи більше разів;
- пряма риска | – означає навність вибору з двох чи більше можливостей. Наприклад, позначення ASC|DESC указує: можна вибрати один із термінів ASC чи DESC; коли ж один з елементів вибору укладений у квадратні дужки, то це означає, що він вибирається за замовчуванням (наприклад, [ASC]|DESC означає, що відсутність усієї цієї конструкції буде сприйматися як вибір ASC);
- крапка з комою (;) – завершальний елемент операторів SQL;
- кома (,) – використовується для відокремлення елементів списків;
- пробіли ( ) – можна вводити для підвищення наочності між будь-якими синтаксичними конструкціями операторів SQL;
- прописні жирні латинські букви і символи – використовують для написання конструкцій мови SQL і мають (якщо це спеціально не обумовлено) записуватися точно так, як показано;
- малі літери – використовуються для написання конструкцій, що мають бути замінені конкретними значеннями, обраними користувачем, причому для визначеності окремі слова цих конструкцій зв’язують між собою символом підкреслення _.
Управління полями таблиці з допомогою оператора SELECT.
Управління полями полягає у виборі полів таблиці (таблиць), які мають увійти в результатний набір даних. Приклад відбору всіх полів у таблиці:
select * from stat
За цим запитом із таблиці stat у результатний набір даних потрапляють усі поля і всі записи. При цьому порядок полів у наборі даних відповідає порядку фізичних полів у таблиці.
Приклад перегляду кількох таблиць одночасно:
select *
from stat
select *
from obsag
На цей запит із таблиць stat і obsag виводяться всі поля і всі записи таблиць.
Якщо потрібно вибрати дані лише з кількох полів таблиці, то після слова SELECT перелічуються через кому в потрібному порядку назви цих полів. Порядок полів у наборі відповідатиме порядку полів у списку. Якщо ім’я поля вказано у списку неодноразово, то в наборі даних буде кілька стовпців з однаковими іменами і даними. Наприклад:
select cod, osvita
from stat
На виконання цього SQL-запиту здійснюється відбір із таблиці записів тільки двох полів: cod, osvita.
Крім фізичних полів таблиць, у набір даних можна включати розрахункові поля. Для отримання розрахункового поля у списку полів вказується не ім’я цього поля, а вираз, за яким розраховується його значення. Наприклад:
select cod, suma, suma – 20
from obsag
У полі suma – 20 виведеться значення поля suma, зменшене на 20.
Записи можуть мати однакові значення деяких полів. Для того, щоб включити в набір даних тільки записи з унікальними значеннями, перед списком полів вказується описувач DISTINCT:
SELECТ DISTINCT <ім’я поля>, <ім’я поля >
FROM <ім’я таблиці>
Наприклад, потрібно вивести з таблиці obsag коди рекламних агентів, які виконали операції:
select distinct cod
from obsag
У результаті виконання запиту виведеться список кодів, які не повторюються.
Використання простих критеріїв відбору записів із таблиць.
У попередніх прикладах у набір даних потрапляли всі записи із вказаних таблиць. На практиці набір даних обмежується записами, які задовольняють певним умовам (критеріям) відбору, які задаються за допомогою операнда WHERE.
Критерій відбору – це логічний вираз, у якому можна використовувати операції:
= – дорівнює;
> – більше;
< – менше;
>= – більше-рівне;
<= – менше-рівне;
<> або != – не рівне;
!> – не більше;
!< – не менше;
LIKE – порівняння за шаблоном;
IS NULL – перевірка на нульове значення;
IN – перевірка на входження;
BETWEEN – перевірка на входження в діапазон.
Для операцій порівняння і порівняння за шаблоном критерій відбору такий:
<Вираз1> <Операція порівняння> <Вираз2>
Використання операторів порівняння.
Вираз може складатися з імен полів, функцій, констант, значень, знаків арифметичних операцій та круглих дужок. Найпростіші вирази складаються з імен полів або значення. Наприклад:
select cod
from obsag
where suma>= 1500
Цей оператор створює список кодів працівників, які виконали операції на суму не меншу ніж 1 500 грн. Наведемо приклад відбору записів за значеннями символьного поля:
select prizv
from stat
where osvita = ‘вища’
У цьому прикладі в операції порівняння враховується регістр символів. Слова «Вища» і «вища» не рівні між собою. Різниця в регістрі символів або наявність початкових і кінцевих пробілів прозводить до помилок при відборі записів. У цьому разі критерій відбору доцільно записати так:
where upper(trim(osvita)) = ‘вища’
Функція TRIM знищує початкові і кінцеві пробіли, а функція UPPER приводить символи рядка до верхнього регістру. В результаті значення поля «Вища» буде приведена до значення «ВИЩА».
Використання LIKE.
Для порівняння рядків замість операцій =, !=, <> можна використовувати операцію LIKE, яка виконує порівняння за частковим збігом. Частковий збіг значень доцільно перевіряти, наприклад, коли відома тільки початкова частина прізвища:
select prizv
from stat
where prizv like ‘Ac%’
У результаті отримаємо список прізвищ, які починаються на літери «Ac».
У виразах операції LIKE допускається застосування шаблону, в якому можна використовувати всі алфавітно-цифрові символи (з урахуванням регістру). При цьому два символи мають спеціальне призначення:
% – заміняє будь-яку кількість символів, у тому числі й нульовий;
_ – заміняє один символ.
За допомогою шаблону можна виконати перевірку на частковий збіг не тільки початкових символів рядка, а й знайти входження заданого фрагмента в будь-яку частину рядкового значення. Наприклад:
select prizv
from stat
where prizv like ‘% р %’
Перед операцією LIKE можна використовувати описувач NOT, який змінює результат виконання операції на протилежне значення і перевіряє значення виразів на незбіжність.
Для перевірки нульового значення виразу служить операція IS NULL, яка має такий формат:
<Вираз> IS [NOT] NULL
Наприклад,
select *
from stat
where stag is null
У цьому запиті відбираються всі записи таблиці stat, які мають нульові значення в полі stag.
Використання IN.
Перевірка на входження значення виразу в список виконується з допомогою операції IN такого формату:
<Вираз> [NOT] IN <Список значень>
Цю операцію зручно виконувати, якщо вираз може приймати невелику кількість різних значень. Наприклад:
select cod, prizv
from stat
where osvita in (‘середня’, ‘вища’)
У результаті отримаємо вибірку кодів і прізвищ усіх працівників із середньою або вищою освітою.
Використання BETWEEN.
Операція BETWEEN виконує перевірку входження значення в діапазон. Вона має такий формат:
<Вираз> [NOT] BETWEEN
<Мінімальне значення> AND <Максимальне значення>
Під час виконання цієї операції в набір даних включаються записи, для яких значення виразу більше або рівне мінімальному, а також менше або рівне максимальному значенням. Описувач NOT змінює результат операції на протилежний.
Розглянемо приклад:
select *
from stat
where data_nar between ‘01/01/1960’ and ‘12/01/1980’
У результаті виконання такого запиту отримаємо набір записів, для яких дата народження (поле data_nar) міститься в діапазоні з 1 січня 1960 року до
1 грудня 1980 року.
Використання HAVING.
Операція HAVING відіграє таку ж роль для груп, як і WHERE для рядків. Ця операція включається в оператор за наявності GROUP BY.
Використання складених критеріїв відбору записів із таблиць.
Для відбору можна використовувати кілька операцій, задаючи тим самим складені критерії відбору записів. Складений критерій (логічний вираз) складається:
- з простих умов;
- логічних операцій: AND (логічне І), OR (логічне АБО), NOT (логічне НЕ);
- круглих дужок.
У мові SQL пріоритет операцій порівняння вищий за пріоритет логічних операцій. Для зміни порядку виконання операцій використовують круглі дужки.
Приклади запитів із складеним критерієм відбору:
select prizv
from stat
where osvita = ‘вища’ and adressa =‘Львів’
Цей запит відбирає прізвища працівників, які мають вищу освіту і домашню адресу – Львів.
select prizv
from stat
where osvita = ‘вища’ or osvita = ‘cередня’
Цей запит відбирає прізвища працівників, які мають вищу або середню освіту.
select prizv
from stat
where (osvita = ‘вища’) and
(data_nar between ‘01.01.1960’ and ‘12.01.1980’)
Запит відбирає прізвища працівників, які мають вищу освіту і народилися в період із 1 січня 1960 року до 1 грудня 1980. У цьому логічному виразі прості умови записані в дужках, але це не обов’язково, оскільки пріоритет операцій порівняння вищий від пріоритету логічних операцій.
Агрегування даних. SQL-функції.
У SQL є низка стандартних функцій (SQL-функцій). Крім спеціального випадку функції COUNT(*), кожна з цих функцій оперує сукупністю значень поля певної таблиці і створює єдине значення, яке визначають так: COUNT – кількість значень у полі, SUM – загальна сума в полі, AVG – середнє значення поля, MAX – найбільше значення поля, MIN – найменше значення поля. Для функцій SUM і AVG поле має бути числового типу. Зазначимо, що тут поле – це поле віртуальної таблиці, в якій можуть міститися дані не тільки з поля базової таблиці, а й дані, отримані шляхом функціонального перетворення і(або) зв’язування символами арифметичних операцій значень з одного або кількох полів. Із SQL-функцій можна складати будь-які вирази. Перед аргументами всіх функцій, крім COUNT(*), можна ставити ключове слово DISTINCT (різний), яке вказує, що значення, які дублюються, мають бути виключені перед тим, як буде застосовуватися функція. Спеціальна функція COUNT(*) служить для підрахунку всіх без винятку рядків у таблиці (включаючи дублікати).
Записи набору даних можуть бути згруповані за якоюсь ознакою. Групу утворюють записи з однаковими значеннями в полях, перелічених у списку операнда GROUP BY.
Групування записів автоматично виключає повтор значень у полях, заданих для групування, оскільки записи із збіжними значеннями цих полів об’єднуються в одну групу.
Приклад запиту з групуванням записів:
select data_nar, count (data_nar)
from stat
where data_nar between ‘01.01.1960’ and ‘01.01.1980’
group by data_nar
Для кожної дати з указаного періоду виводиться кількість записів, де вона зазначена. Якщо не виконати групування, то в набір даних потраплять усі записи, а при групуванні всі записи отриманого набору даних унікальні. Функція COUNT виводить для кожної групи (сформованої за полем дати народження) кількість записів у групі.
У результаті виконання запиту виведеться загальна сума операцій, виконаних кожним рекламним агентом.
select cod, sum (suma)
from obsag
group by cod
Максимальну суму операції кожного рекламного агента можна вибрати за допомогою запиту:
select cod, max (suma)
from obsag
group by cod
Сортування записів.
Сортування – це впорядкування записів за зростанням або спаданням значень полів. Список полів, за якими здійснюється сортування, вказується в операнді ORDER BY. Порядок полів у цьому операнді визначає порядок сортування: спочатку записи впорядковують за значенням поля, вказаного в цьому списку першим, потім записи, які мають однакові записи першого поля, впорядковують за значенням другого поля і т. д.
Поля у списку позначають іменами або номерами, відповідними до номерів полів у списку після слова SELECT. За замовчуванням сортування здійснюється в порядку зростання значень полів. Для протилежного напряму сортування слід указати після імені поля описувач DESC.
Приклад запиту на сортування записів:
select *
from stat
order by prizv
Тут сортування записів задано за полем prizv.
Приклад запиту на сортування за двома полями:
select prizv, stag
from stat
order by prizv, stag desc
У результатний набір даних увійдуть поля prizv, stag усіх записів. Записи посортовані за полями prizv, stag, при цьому значення поля stag упорядковано за спаданням.
Ще одна перевага мови SQL – це простота об’єднання даних, які містяться в кількох таблицях. Для цього після слова FROM перераховують імена таблиць, із записів яких формується набір даних:
SELECT *
FROM <ім’я таблиці_1>, < ім’я таблиці_2>
або
SELECT <ім’я таблиці_1.*>, <ім’я таблиці_2.*>
FROM <ім’я таблиці_1>, <ім’я таблиці_2>
Результатний набір даних становлять усі поля і всі записи з двох таблиць. Спочатку розміщаються поля першої таблиці, далі – поля другої таблиці.
Відбір конкретних полів із двох таблиць виконується оператором:
SELECT <ім’я таблиці_1.ім’я поля>, <ім’я таблиці_2.ім’я поля>
FROM <ім’я таблиці_1>, <ім’я таблиці_2>
Якщо імена полів унікальні (не повторюються), то в запиті імена таблиць у визначенні полів не вказуються:
SELECT <ім’я поля>, <ім’я поля>
FROM <ім’я таблиці_1>, <ім’я таблиці_2>
Зв’язування таблиць.
У набір даних можна включати поля з різних таблиць. Таке включення полів називається зв’язуванням таблиць. Зв’язування таблиць може бути внутрішнім і зовнішнім.
Внутрішнє зв’язування таблиць – це найпростіший випадок, коли після слова SELECT перелічуються поля різних таблиць.
Таблиці stat і obsag містять основні і додаткові дані про рекламних агентів. Таблиці зв’язані відношенням «один-до-багатьох», тобто кожному запису першої таблиці відповідає кілька записів іншої таблиці. Результатний набір даних є об’єднанням полів двох таблиць таким чином, ніби додаткові дані з’єднуються з основними. У таблицях можуть бути вибрані не всі поля, але це не змінює принципу з’єднання.
У разі використання внутрішнього з’єднання таблиць із відношенням «один-до-багатьох» результат виконання запиту може містити надлишкову інформацію. Для того, щоб у результатному наборі даних отримати повну інформацію про здійснені операції, слід скористатися запитом із внутрішнім з’єднанням таблиць, зв’язаних відношенням «один-до-багатьох». Наприклад,
select *
from stat, obsag
where stat.cod = obsag.cod
У результаті виконання запиту виведуться всі поля і записи таблиці obsag і всі поля таблиці stat.
Для того, щоб отримати інформацію про працівників і всі операції (суму інформацій), які вони виконали, можна скористатися запитом:
select stat.cod, stat.prizv, obsag.suma
from stat, obsag
where stat.cod = obsag.cod
У результаті виконання запиту виведуться всі записи полів cod i prizv таблиці stat, а також значення полів suma таблиці obsag, що відповідають конкретним працівникам.
select *
from stat, obsag
where stat.cod = obsag.cod
order by stat.cod
У результаті виконання запиту виведуться всі поля і записи таблиці obsag і всі поля таблиці stat, причому записи будуть посортовані за полем cod.
У цих запитах застосовується критерій відбору, що обмежує склад записів: кількість записів результатного набору даних дорівнює кількості записів таблиці «Обсяг операцій» (obsag), тому що відбираються тільки записи, для яких збігаються значення полів коду.
Без використання операнда WHERE результатний набір даних буде містити також записи з рекламними агентами, що не виконали жодної операції.
За внутрішнього зв’язування всі таблиці, поля яких вказані в SQL-запиті, є рівноправними.
За зовнішнього зв’язування таблиць можна вказати, яка з таблиць буде головною, а яка – підлеглою. У разі використання зовнішнього зв’язування оператор FROM має такий формат:
FROM <Таблиця1> [< Вид зв’язування>] JOIN <Таблиця2>
ON <Критерії відбору>
Критерій відбору після слова ON задає умову включення записів у набір даних, зі зв’язаних таблиць, зліва і справа від слова JOIN. Яка з таблиць буде головною, визначає вид зв’язування:
LEFT – головна таблиця вказана зліва;
RIGHT – головна таблиця вказана справа (за замовчуванням).
Запит, у якому використовується зовнішнє зв’язування таблиць:
select *
from stat left join obsag
on stat.cod = obsag.cod
Зв’язуються таблиці «Штат рекламних агентів» (stat) і «Обсяг операцій» (obsag). Головною є таблиця stat.
Вкладені запити.
Запити можуть керувати іншими запитами. Це робиться шляхом вкладання одного запиту всередину умови другого запиту. Зазвичай внутрішній запит генерує значення, яке перевіряється в умові зовнішнього запиту, який визначає, правильне воно чи ні. Наприклад, відоме ім’я торговельного агента – Шостак Т. Х., але не відомий його код (cod). Треба вибрати всі здійснені ним операції з таблиці «Обсяг операцій» (obsag). Запит матиме такий вигляд:
select *
from obsag
where cod = (select cod
from stat
where prizv =‘Шостак Т.Х.’)
Щоб виконати зовнішній (головний) запит, спочатку виконується внутрішній запит (підзапит) усередині оператора where. При виконанні підзапиту розглядається таблиця «Штат рекламних агентів» (stat), у якій вибираються рядки, де поле prizv рівне ‘Шостак Т.Х.’, далі вибирається значення поля cod. Єдиним рядком буде cod=101. Далі отримане значення поміщається в умову головного запиту, замість самого підзапиту, так що умова набуде вигляду: where cod=101. У результаті головний запит виконується як звичайний.
Приклади вкладених запитів:
select *
from obsag
where suma < ( select avg(suma)
from obsag)
У результаті виконання запиту отримаємо дані про операції, здійснені на суму, меншу за середньоарифметичну.
select *
from stat
where cod = ( select cod
from obsag
where month (data)=6 )
У результаті виконання запиту отримаємо cписок рекламних агентів, які здійснили операції в червні.
Використання математичних та рядкових функцій:
Математичні функції
Математичні функції застосовуються до числових типів даних, таких, як INTEGER, FLOAT, REAL, MONEY (табл. 12.1). Вони знаходять значення з точністю до шести десяткових розрядів. Якщо при виконанні функції виникла помилка, то результат приймає значення NULL і з’являється повідомлення про помилку.
Таблиця 12.1
Основні математичні функції SQL
|
ACOS (float) |
Арккосинус числа |
|
ASIN (float) |
Арксинус числа |
|
CEILING (numeric) |
Найменше ціле значеня, яке більше або рівне значенню виразу |
|
FLOOR (numeric) |
Найбільше ціле значеня, яке більше або рівне значенню виразу |
|
EXP (float) |
Експонента значення виразу |
Продовження табл. 12.1
|
LOG10 (float) |
Десятковий алгоритм значення виразу |
|
LOG (float) |
Натуральний алгоритм значення виразу |
|
POWER (numeric, y) |
Значення виразу в степені y |
|
ABS (numeric) |
Абсолютне значення виразу |
|
RAND (integer) |
Випадкове дійсне число, яке міститься в проміжку від 0 до 1 або до значення, вказаного в необов’язковому аргументі |
|
ROUND (numeric, integer) |
Округлення значення з точністю до integer |
|
SQRT (float) |
Квадратний корінь від значення виразу |
Приклади використання математичних функцій:
обчислення кореня квадратного з числа 81:
- select sqrt (81);
- заокруглення значення числа 8.8888 із точністю до двох знаків після коми:
- select round (8.8888,2);
- select round (sqrt(7),2);
- знаходження значення 563:
- select power (56,3);
- знаходження найменшого цілого значення поля suma:
- select ceiling (suma)
from obsag.
Рядкові функції.
Основні рядкові функції SQL наведено в табл. 12.2.
Таблиця 12.2
|
ASCII (char) |
Знаходить ASCII-код символу, який є крайнім зліва у виразі |
|
CHAR (integer) |
Перетворює ASCII-код у символ |
|
LOWER (char) |
Перетворює великі літери в малі |
|
UPPER (char) |
Перетворює малі літери у великі |
|
LTRIM (char) |
Знищує пробіли на початку рядка |
|
RTRIM (char) |
Знищує пробіли в кінці рядка |
|
STR(float[,length [,decimal]]) |
Перетворює числові дані в символьні |
Приклади використання рядкових функцій:
- перетворення символу в десятковий ASCII-код і навпаки:
- select ASCII (‘Apple’);
- select char (65);
- знищення пробілів на початку і в кінці рядка;
- select rtrim (ltrim (‘ Apple ‘);
- міняє регістр символів;
- select lower (‘ABCD’).
Функції для роботи з датою.
Для виконання операцій над даними типу DATE є кілька функцій. Їх використовують для виконання арифметичних операцій над даними типу DATETIME і SMALLDATETIME (табл. 12.3).
Таблиця 12.3
Основні функції для роботи з датою SQL
|
DATENAME(date_part, date) |
Перетворює певну частину дати в символьний рядок |
|
DATEPART (date_part, date) |
Перетворює певну частину дати в дане цілого типу |
|
GETDATE () |
Перетворює дату і час у стандартний формат SQL Server і має тип DATETIME |
|
DATEADD (date_part, number, date) |
Знаходить значення, яке дорівнює вказаній |
|
DATEDIFF (date_part, date1, date2) |
Знаходить різницю між частинами двох різних дат |
Приклади використання функції для роботи з датою:
- перетворення символа в десятковий ASCII-код і навпаки:
- select ASCII (‘Apple’);
- select char (65);
- знищення пробілів на початку і в кінці рядка:
- select rtrim (ltrim (‘ Apple ‘);
- міняє регістр символів:
-select lower (‘ABCD’).
13. Створення та використання таблиць бази даних засобами SQL Server Enterprise Manager
Додаток SQL Server Enterprise Manager використовується для виконання практично всіх адміністративних операцій як для локальних, так і віддалених серверів. Крім цього, утиліта SQL Server Enterprise Manager застосовується також для виконання таких операцій:
- керування обліковими записами користувачів і підключення до сервера;
- виконання резервного копіювання, відновлення баз даних і журналів транзакцій;
- запуск, зупинка і конфігурування серверів;
- перевірка узгодженості бази даних;
- відображення статистики роботи сервера;
- створення і керування об’єктами і задачами бази даних;
- створення і контроль за обліковими записами і групами користувачів;
- контроль за списками доступу.
SQL Server поміщає в бази даних таблиці та індекси. Фізично база даних розміщується в одному або декількох файлах операційної системи. Перш ніж приступити до розробки таблиць та інших структур бази даних необхідно створити сам файл бази даних. Початковою точкою створення нової бази даних в SQL Server служить шаблон, або модель бази даних. Модель бази даних містить стандартні об’єкти, на основі яких можна розробляти свої власні. Отже, модель бази даних містить наступні стандартні об’єкти SQL Server:
- Database Users (користувачі бази даних). Єдиним користувачем, який існує в стандартній системі є dbo;
- Database Roles (ролі бази даних). Визначено десять стандартних ролей;
- Tables (таблиці). Це сховища даних; уся системна інформація зберігається, відповідно, в системних таблицях. В стандартну модель включено сімнадцять таблиць, на основі яких можна будувати свої власні таблиці;
- Views (вигляди). Об'єкти, аналогічні до таблиць, але вони представляють не усю вихідну таблицю, а її підмножину чи результат об'єднання декількох базових таблиць; вигляд завжди ґрунтується на SQL-запиті. Передбачено двадцять виглядів, які можуть відображати інформацію, що вибирається із таблиць бази даних;
- Stored Procedures (збережені процедури). Це засіб реалізації обробки даних на сервері, сценарії мовою SQL, які виконуються на сервері; зберігаються як у вихідному, так і в скомпільованому вигляді; використовуються самим SQL-сервером для виконання всіх адміністративних акцій. В моделі бази даних немає ні однієї процедури;
- Rules (правила). При додаванні поля, чи його зміні перевіряють допустимість даних; правило може бути зв'язане з полями декількох таблиць у базі. В модель бази даних правила не включені;
- Defaults (стандартні установки). В моделі бази даних стандартних установок немає.
- DatabaseDiagrams (діаграми бази даних). В модель бази даних діаграми не включені;
- User-Defined Datatypes (типи даних, які визначаються користувачем).
Керування моделлю бази даних здійснюється звичайним чином, і кількість об’єктів, які в неї можна помістити – необмежена. Саме для роботи з різними об’єктами бази даних використовується програма SQL Server Enterprise Manager.
Створення таблиць.
При застосуванні додатку SQL Server Enterprise Manager для створення таблиць існує можливість використовувати переваги графічного інтерфейсу при визначенні різноманітних атрибутів таблиці. До них відносяться типи даних, довжина полів і т.д. Для створення таблиць потрібно виконати наступні дії:
1. Запустити додаток SQL Server Enterprise Manager.
2. Виконати реєстрацію SQL Server (див. Інструкція № 1).
3. Відкрити папку Databases, клікнувши на розміщеному поряд з нею знаку „+”. Клікнути на потрібній базі даних, щоб вибрати її. В цій базі даних буде створена таблиця. Відкрити базу даних, клікнувши на розміщеному поряд з нею знаку „+” (рис. 13.1).

Рис. 13.1 - Вікно бази даних зі списком елементів, до якої можна добавити нову таблицю
1. Клікнути правою кнопкою миші на елементі Tables (Таблиці) і вибрати команду New Table... У вікні, яке з’явиться „New Table in” (Створити таблицю) (рис. 13.2) задати структуру таблиці.
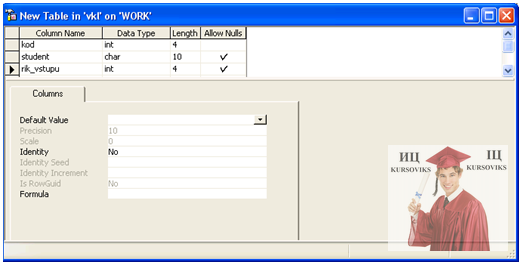
Рис. 13.2 - Вікно створення таблиці бази даних
2. В поле Column Name (Ім’я поля) ввести ім’я поля. Імена полів записуються латинськими літерами.
3. З допомогою миші або клавіші Тав перейти в поле Data Тype (Тип даних). У списку, який з’явиться, вибрати тип даних.
4. Якщо у вибраного типу даних є специфікація довжини, то ввести значення довжини в поле Length (Довжина).
5. Щоб визначити елементи NULL, потрібно залишити прапорець в полі Allow Nulls (Дозволити нулі) встановленим.
6. Якщо заздалегідь встановлені стандартні значення, можна вибрати одне із них в полі Default (Стандартне значення).
7. Повторити пункти 3-7, щоб визначити всі необхідні стовпці та їх характеристики (можна визначити до 1024 стовпців).
8. Щоб зберегти таблицю, потрібно клікнути на піктограмі Save, яка розміщена на панелі інструментів. В діалоговому вікні Choose Name (Вибір імені) ввести ім’я таблиці. Клікнути на кнопці ОК (Рис. 13.3).
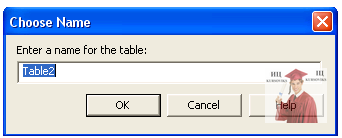
Рис. 13.3 - Вікно збереження таблиці
Зміна складу полів таблиці.
Зміна складу полів таблиці полягає у додаванні або видаленні полів, зміні імені та типу поля, що призводить до зміни структури таблиці. Щоб змінити структуру таблиці, необхідно клікнути правою кнопкою миші на імені таблиці і з контекстного меню вибрати команду DesignTable, або виконати команду Действие - DesignTable.
Додавання первинних і вторинних ключів.
Щоб додати первинний ключ з допомогою програми SQL Server Enterprise Manager, потрібно:
1. Клікнути правою кнопкою миші на полі, яке повинно бути ключовим, і з контекстного меню вибрати команду SetPrimaryKey (Встановити первинний ключ) або клікнути на кнопці із зображенням ключа, яка розміщена на панелі інструментів.
2. Для збереження змін у таблиці виконати команду Save.
Встановлення зв’язків між таблицями.
На одній із двох таблиць, які беруть участь у зв’язках клікнути правою кнопкою миші і вибрати з контекстного меню команду Design Table. На панелі інструментів активізувати кнопку Table and Index Properties. У вікні Properties необхідно вибрати вкладку Relationships і для створення нового зв’язку клікнути на кнопці New.
У полі Relationships name відображається назва зв’язку. У полі Primary key table (ліва панель) зі списку необхідно вибирати головну таблицю зв’язку, а у полі Foreign key table (права панель) – підпорядковану таблицю зв’язку. Зі списків, що розміщені нижче вибираємо поля, по яких встановлюється зв’язок. Для остаточного встановлення зв’язку необхідно натиснути кнопку Закрити.
Переглянути і видалити зв’язки можна у вікні Properties у полі Selected relationships. Для цього необхідно вибрати зв’язок зі списку і натиснути кнопку Delete.
Модифікація записів у таблиці.
Модифікація записів передбачає редагування записів, додавання нових записів, видалення існуючих записів. Редагування записів передбачає зміну значень полів у записі. Записи можна копіювати із однієї таблиці в іншу, якщо їхні структури співпадають. Для додавання записів у таблицю треба клікнути правою кнопкою миші на імені таблиці і з контекстного меню вибрати команду Open Table – Return all rows….
Відбір даних із таблиць за допомогою графічних інструментів SQL Server.
При використанні додатку SQL Server Enterprise Manager для створення запитів використовуються переваги графічного інтерфейсу. Для створення запитів необхідно завантажити додаток SQL Server Enterprise Manager.
Із контекстного меню вибрати команду Open Table-Query. З’явиться вікно для побудови запиту Query Designer, яке складається з чотирьох панелей: панелі діаграм, панелі проектування запиту, панелі sql команд, панелі результату (рис. 13.4).
Панель діаграм (Show/Hide Diagram Pane) відображає таблиці з яких будуть вибиратись дані.
Панель проектування запиту (Show/Hide Grid Pane) – це таблиця параметрів запиту.
Панель sql команд (Show/Hide SQL Pane) відображає набір операторів мови SQL, які виконують спроектований запит.
Панель результату (Show/Hide Results Pane) містить результат запиту.
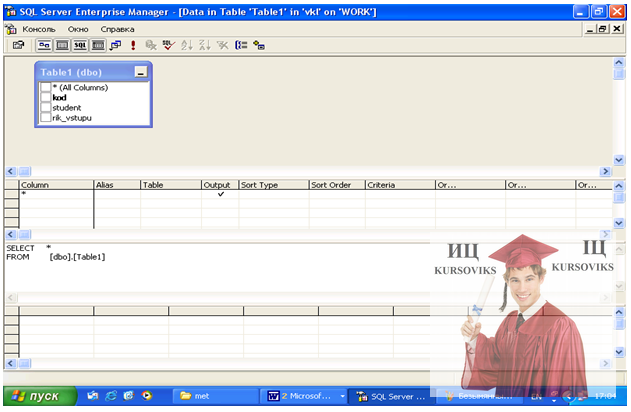
Рис. 13.4 - Вікно побудови запиту
Панель діаграм дозволяє:
- додавати (на панелі інструментів клікнути на кнопці Add Table і вибрати потрібну таблицю) або видалити (клікнути правою кнопкою миші на таблиці і з контекстного меню вибрати команду Remove) таблиці запиту;
- вибирати поля, які потрібно відображати (поставити прапорець біля поля відповідної таблиці). Знак * (All Columns) дозволяє вибрати у запит всі поля таблиці;
- створювати зв’язки між таблицями.
Панель проектування запиту має наступні параметри:
- Column – дозволяє вибирати поле таблиці у запит;
- Alias – дозволяє задати назви колонок у запиті;
- Тable – ім’я таблиці з якої вибрано поле;
- Output – дозволяє відображати або не відображати вибране поле у запиті;
- SortType – дозволяє задати порядок сортування поля у запиті (Ascending – по-зростанню, Descending – по-спаданню);
- SortOrder – задає пріоритет сортування;
- Criteria – задає умови вибірки (фільтр) даних для поля.
Для виконання запиту необхідно на панелі інструментів натиснути кнопку ! (Run) або із контекстного меню вибрати команду Run. Результат запиту буде виведено на Панелі результату.
14. Проектування реляційної бази даних
Проект реляційної бази даних – це набір взаємозв’язаних відношень (таблиць), в яких визначені всі атрибути, задані первинні ключі відношень, а також інші додаткові властивості відношень, які забезпечуватимуть цілісність бази даних. Проект бази даних повинен бути дуже точним і вивіреним. Фактично, проект бази даних – це фундамент майбутньої інформаційної системи, яка може довго використовуватися багатьма користувачами.
Процес проектування бази даних – це послідовність переходів від неформального словесного опису інформаційної структури предметної області до формалізованого опису об’єктів предметної області в термінах деякої моделі. Етапи проектування бази даних і додатку бази даних детально розглядалися нами у розділі 5. Узагальнюючи матеріал цього розділу, можна зробити висновок, що процес проектування бази даних зводиться до наступних кроків:
- системний аналіз і словесний опис інформаційних об’єктів предметної області;
- формалізований опис об’єктів предметної області в термінах деякої моделі;
- логічне проектування бази даних, тобто опис бази даних в термінах прийнятої моделі даних;
- фізичне проектування бази даних, тобто вибір ефективного розміщення бази даних на зовнішніх носіях для забезпечення найбільш ефективної роботи додатків.
Системний аналіз предметної області.
При проектуванні бази даних необхідно виконати перший етап, тобто здійснити:
- детальний словесний опис об’єктів предметної області і реальних зв’язків, які існують між цими об’єктами;
- формулювання конкретних задач, які будуть розв’язуватися з використанням даної бази даних, з коротким описом алгоритмів їх розв’язку;
- опис вихідних документів, які повинні генеруватися в системі;
- опис вхідних документів, які служать основою для занесення даних.
Розглянемо на конкретному прикладі опис предметної області. Нехай необхідно розробити інформаційну систему для автоматизації управління навчальним процесом в навчальному закладі. Для того, щоб уникнути надто складних пояснень і при цьому адекватно вiдобразити суть процесу проектування, зробимо припущення, що навчальний процес триватиме лише один рік (два семестри) і кожну дисциплiну читає лише один викладач.
Система повинна передбачати режими накопичення облікових оперативних даних про студентів, відображати процес навчання студента у навчальному закладі. Також необхідно передбачити засоби аналізу та обробки накопичених даних і засоби генерації звітних документів, які відповідають освітнім стандартам. Крім того система повинна передбачати підтримку таблиць довідкових даних (довідників), наприклад, даних про факультети, викладачів, дисципліни, тощо. До облікових даних відносяться:
- код студента;
- прізвище, ім’я, по-батькові;
- дата народження;
- дата вступу в інститут;
- паспортні дані студента;
- наявність пільг;
- іноземна мова, яку буде вивчати студент;
- контактні дані студента;
- замовники навчання.
В списку можуть бути студенти однофамільці, тому кожному студенту присвоюється унікальний код, який забезпечує однозначну ідентифікацію.
Протікання навчального процесу зв’язано з накопиченням різноманітних оперативних даних, до яких можна віднести інформацію про академічні групи, навчальні плани, успішність.
Кожна група характеризується наступними параметрами:
- унікальний код;
- назва групи;
- факультет;
- спеціальність;
- куратор;
- навчальний план.
Студенти групи навчаються за конкретним навчальним планом, який містить наступні дані:
- код навчального плану;
- ознака семестру, в якому читається дисципліна;
- дисципліна;
- кількість годин на вивчення дисциплін;
- форма контролю;
- викладач.
Інформаційна система повинна забезпечувати облік успішності студентів. Інформація про успішність за результатами семестрового контролю має наступні характеристики:
- прізвище, імя, по-батькові студента;
- назва дисципліни;
- назва групи;
- спеціальність;
- прізвище, імя, по-батькові викладача;
- оцінка;
- дата отримання оцінки.
При проектуванні необхідно врахувати (передбачити) наступні обмеження:
- кожен студент при поступленні у навчальний заклад повинен бути не старшим за 35 років. Для цього обов’язково має бути параметр дата народження;
- оцінка – обов’язковий атрибут результатів семестрового контролю;
- кількість годин у навчальному плані не може мати нульового значення;
- ознака семестру може приймати значення від 1 до 10.
З даними інформаційної системи будуть працювати наступні групи користувачів:
- деканати;
- бухгалтерія;
- профспілка;
- куратори академічних груп.
Інформаційна система повинна виконувати наступні задачі:
- формувати екзаменаційну та залікову відомості;
- формувати зведені відомості як за результатами семестрового контролю, так і за результатами всього періоду навчання;
- формувати відомість рейтингу студентів;
- формувати довідкову інформацію про студентів у різноманітних розрізах (список студентів, адресний список, пільговий список, мовний список і т.д.);
- формувати талони про перездачу іспитів;
- формувати додатки до дипломів;
- формувати особові картки студентів (зріз даних про студента, всякому містяться облікові дані й дані про успішність студента на даний момент);
- проводити верстку навчальних планів;
- відслідковувати внутрішні переміщення студентів в межах інституту;
- формувати дані статистичної звітності про контингент студентів.
Логічне проектування.
У реляційних базах даних логічне проектування приводить до розробки схеми бази даних, тобто сукупності схем відношень, які адекватно моделюють абстрактні об’єкти предметної області і зв’язки між цими об’єктами. Основою аналізу коректності схеми є функціональні залежності між атрибутами відношень бази даних. Атрибут – це властивості, які описують характеристики елемента (запису) відношення. Коректною буде така схема бази даних, в якій відсутні небажані залежності між атрибутами відношень.
Іншими словами, логічне проектування дозволяє перейти від словесної форми опису предметної області до структурованої табличної форми її опису. Тобто представити всі наявні у предметній області відношення у вигляді таблиць та зв’язків між ними.
У результаті першого етапу проектування ми отримали модель бази даних, яку можна представити у вигляді таблиць (рис. 14.1):
Рис. 14.1 - Таблиці з вихідними даними
В основі процесу проектування лежить метод нормалізації, який полягає в декомпозиції відношень, які знаходяться в попередній нормальній формі, в два або більше відношень і які задовольняють вимоги наступної нормальної форми (див. розділ 4.1).
Нагадаємо, що таблиця знаходиться в першій нормальній формі (1НФ), якщо в будь-якому допустимому значенні цієї таблиці кожний її рядок містить тільки одне значення для кожного атрибуту (стовпця). Для приведення таблиць, зображених на рис. 17, до 1НФ небхідно, щоб кожна з них містила тільки логічно неподільні значення. Наприклад, таблиця Облікові дані студентів містить поля Контактні дані і Паспортні дані, які включають множину значень. Тому доцільно ці дані виділити в окремі таблиці, які матимуть наступний вигляд (рис. 14.2):
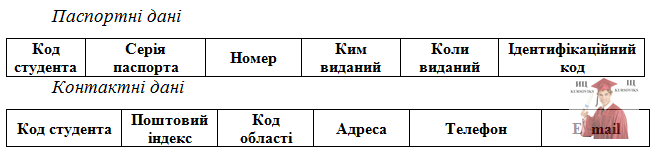
Рис. 14.2 - Таблиці 1НФ
Тепер всі таблиці знаходяться в 1НФ, оскільки кожен стовпець таблиці неподільний і в рамках однієї таблиці немає стовпців з однаковим за змістом значенням.
Наступна задача проектування бази даних зводиться до скорочення надлишковості даних у базі даних, а значить, до економії об’єму пам’яті, зменшення витрат на багаторазові операції поновлення надлишкових копій і усунення можливості виникнення протиріч через зберігання в різних місцях відомостей про один і той самий об’єкт. В приведених таблицях структури бази даних, зображених на рис. 14.1, спостерігається надлишковість. Наприклад, оскільки атрибут ПІП студента присутній у таблицях Облікові дані студентів та Успішність, то при його зміні необхідно робити виправлення у двох таблицях. Хороша структура бази даних містить по одному елементу інформації і лише в одному місці, що й дозволить уникнути надлишковості.
Таблиця знаходиться у другій нормальній формі у тому випадку, коли вважається, що вона вже є в 1НФ, і кожний неключовий атрибут повністю залежить від первинного ключа. Крім цього будь-яке відношення, яке знаходиться в 1НФ і не знаходиться в 2НФ, завжди можна перетворити і привести до еквівалентного набору відношень, які знаходяться в 2НФ. Цей процес полягає в заміні відношення, яке знаходиться в 1НФ, набором проекцій, еквівалентних початковому. Відповідно об’єднання цих проекцій дасть початкове відношення.
Таблиці структури бази даних, зображених на рис. 14.1 при приведенні до 2НФ заміняються набором відношень. Відношення Облікові дані студентів можна представити набором відношень Облікові дані студентів_1, Мови, Замовники, Пільги з такими первинними ключами Код мови, Код замовника, Код пільги. Відповідно, якщо над відношеннями Облікові дані студентів_1, Мови, Замовники, Пільги провести операцію з’єднання за атрибутами Код мови, Код замовника, Код пільги, то отримаємо відношення Облікові дані студентів.
Аналогічні міркування можна застосувати й до таблиці Навчалні плани, адже у різних навчальних планах зустрiчатимуться однакові дисципліни, що призведе до надлишковості при збереженні назв дисциплін у цій таблиці. Щоб уникнути цього, виділимо назви дисциплін в окрему таблицю Дисципліни, яка має стовпці Код дисципліни і Назва дисципліни. Поле Назва дисципліни в таблиці Навчальні плани замінимо на Код дисципліни. Тим самим ми сформуємо вторинний ключ, який буде зв’язувати таблицю Дисципліни з таблицею Навчальні плани. Те ж саме зробимо з полем Викладач.
Таблиця Навчальні плани через поля Код навального плану та Код дисципліни зв’язує інформацію про групу з дисципліною, яка читається в цій групі, а через поле Код викладача – з викладачем, який читає цю дисципліну. Оскільки одна дисципліна може читатися в двох семестрах, то для однозначної ідентифікації окремого запису таблиці вводиться поле Семестр, яке разом з полями Код навального плану і Код дисципліни утворює складений ключ.
Таким чином в базі даних формуємо всі таблиці-довідники:
1) таблиці-довідники, зв’язані з таблицею Облікові дані студентів:
- Мови;
- Замовники;
- Пільги;
2) таблиці-довідники, зв’язані з таблицею Контактні дані:
- Області;
3) таблиці-довідники, зв’язані з таблицею Інформація про групи:
- Спеціальності;
- Факультети;
- Викладачі;
4) таблиці-довідники, зв’язані з таблицею Навчальні плани:
- Форми контролю;
- Дисципліни;
- Викладачі.
З метою усунення дублювання необхідно внести зміни в структуру таблиці Успішність, а саме: поле ПІП студента замінити на Код студента і зв’зати з таблицею Облікові дані студентів. Замість полів Назва дисципліни, Назва групи, Спеціальність доцільно ввести поле Код навчального плану і встановити зв’язок з таблицею Навчальні плани. Сукупність полів Код студента і Код навчального плану утворює складений ключ, який однозначно ідентифікує інформацію про успішність кожного студента.
Таблиця Успішність через поля Код студента і Код навчального плану зв’язує інформацію про студента з інформацією про конкретну дисципліну і фіксує оцінку, отриману студентом. Оцінка і дата отримання оцінки однозначно залежать від вмістимого полів Код студента і Код навчального плану, які утворюють складений первинний ключ. Таким чином, всі таблиці мають первинні ключі, які однозначно визначають записи і не надлишкові. Тепер можна говорити про те, що таблиці знаходяться в 2НФ.
В результаті проектування отримуємо реляційну модель бази даних, яка складається з таблиць (рис. 14.3):


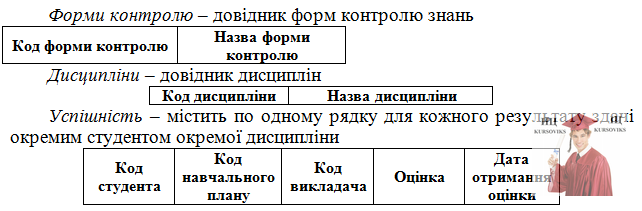
Рис. 14.3 - Таблиці реляційної моделі бази даних
На рис. 14.4 в графічній формі зображенo перелічені таблиці, їх стовпці, первинні і вторинні ключі, зв’язки між таблицями.
Наша структура
Рис. 14.4 - Структура бази даних „Навчальний процес”
Таблиця знаходиться в 3НФ, якщо вона задовольняє і жоден з її неключових атрибутів не зв’язаний функціональною залежністю з будь-яким іншим неключовим атрибутом.
Всі таблиці бази даних „Навчальний процес” знаходяться в 3НФ:
- кожен стовпець таблиці неподільний і в рамках однієї таблиці немає стовпців з однаковими за змістом значеннями (1НФ);
- первинні ключі однозначно визначають запис і є ненадлишковими, всі поля кожної із таблиць залежать від її первинного ключа (2НФ);
- значення довільного поля, яке не входить в первинний ключ, не залежить від значення іншого поля, яке теж не входить в первинний ключ (3НФ).
Наступний етап проектування – визначення типів даних, які зберігаються в стовпцях таблиць. Паралельно із заданням типу необхідно сформулювати обмеження цілісності – перелік допустимих значень типу. Отже, необхідно задати спосіб представлення і межі можливих змін для кожного із стовпців таблиць. При цьому необхідно відповісти на питання: дані яких типів повинні зберігатися в стовпцях і яка максимальна довжина.
Важливим моментом є виділення стовпців, які обов’язково повинні бути заповненими при створенні окремого рядка таблиці. Задаючи таке обмеження цілісності не дозволяємо, наприклад, ввести в таблицю Інформація про групи рядок, в якому не вказана назва групи. Поява в таблиці Інформація про групи рядка без назви групи приведе до помилки при формуванні екзаменаційних (залікових) відомостей.
На рис. 14.5 наведені таблиці бази даних „Навчальний процес” з типами даних стовпців і обмеженнями цілісності на них.
Основні таблиці:
Список полів таблиці „Облікові дані студента” (STUDENT):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_st |
Integer |
Primary key |
Код студента |
|
2 |
Prizv |
Varchar (20) |
Not null |
Прізвище |
|
3 |
Ima |
Varchar (20) |
Not null |
Ім’я |
|
4 |
Pob |
Varchar (20) |
Not null |
По батькові |
|
5 |
Data_nar |
Datetime |
Not null |
Дата народження |
|
6 |
Data_vst |
Datetime |
Not null |
Дата вступу |
|
7 |
Kod_mova |
Integer |
Foreign key |
Код іноз. мови |
|
8 |
Kod_zamov |
Integer |
Foreign key |
Код замовника навчання |
|
9 |
Kod_pilgy |
Integer |
Foreign key |
Код пільги |
|
10 |
Kod_grupa |
Integer |
Foreign key |
Код групи |
Список полів таблиці „Контактні дані студента” (KONTAKT):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_st |
Integer |
Foreign key |
Код студента |
|
2 |
Post_ind |
Varchar (20) |
Not null |
Поштовий індекс |
|
3 |
Kod_oblast |
Integer |
Foreign key |
Код області |
|
4 |
Rajon |
Varchar (20) |
|
Район |
|
5 |
Аdresa |
Varchar (20) |
|
Адреса |
|
6 |
Telef |
Varchar (15) |
|
Контактний телефон |
Список полів таблиці „Паспортні дані студента” (PASPORT):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_st |
Integer |
Foreign key |
Код студента |
|
2 |
Seria |
Varchar (7) |
|
Серія паспорта |
|
3 |
Nomer |
Varchar (6) |
|
Номер паспорта |
|
4 |
Kum_vud |
Varchar (30) |
|
Ким виданий |
|
5 |
Kolu_vud |
Datetime |
|
Коли виданий |
|
6 |
Idetnt_kod |
Varchar (10) |
|
Ідентифікаційний код |
Список полів таблиці „Академічні групи студентів” (GRUPA):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_grupa |
Integer |
Primary key |
Код студента |
|
2 |
Nazva_ grupa |
Varchar (7) |
Not null |
Назва групи |
|
3 |
Kod_fakult |
Integer |
Foreign key |
Код факультету |
|
4 |
Kod_spezial |
Integer |
Foreign key |
Кол спеціальності |
|
5 |
Kod_vyklad |
Integer |
Foreign key |
Код викладача |
|
6 |
Kod_np |
Integer |
Foreign key |
Код навчального плану |
Список полів таблиці „Навчальні плани” (NPLAN):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_np |
Integer |
Primary key |
Код навч. плану |
|
2 |
Kod_discipl |
Integer |
Foreign key |
Код дисципліни |
|
3 |
Semestr |
Integer |
Not null |
Семестр |
|
4 |
Godyny |
Integer |
Not null |
Кількість годин у семестрі |
|
5 |
Kod_fk |
Integer |
Foreign key |
Код підсумкової форми контролю |
|
6 |
Kod_vyklad |
Integer |
Foreign key |
Код викладача |
Список полів таблиці „Дані про успішність студентів” (USP)
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_st |
Integer |
Foreign key |
Код студента |
|
2 |
Kod_np |
Integer |
Foreign key |
Код навч. плану |
|
4 |
Ocinka |
Varchar (10) |
Not null |
Оцінка |
|
5 |
Data_otr |
Datetime |
Not null |
Дата складання іспиту |
|
6 |
Rating |
Integer |
Not null |
Кількість балів |
Таблиці-довідники:
Список полів таблиці-довідника „Області” (OBLAST):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_oblast |
Integer |
Primary key |
Код області |
|
2 |
Nazva_oblast |
Varchar (10) |
Not null |
Назва області |
Список полів таблиці-довідника „Мови” (MOVA):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_mova |
Integer |
Primary key |
Код мови |
|
2 |
Nazva_mova |
Varchar (10) |
Not null |
Назва мови |
Список полів таблиці-довідника „Пільги” (PILGY):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_pilgy |
Integer |
Primary key |
Код пільги |
|
2 |
Nazva_ pilgy |
Varchar (10) |
Not null |
Назва пільги |
Список полів таблиці-довідника „Замовники” (ZAMOV):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_zamov |
Integer |
Primary key |
Код замовника |
|
2 |
Nazva_ zamov |
Varchar (10) |
Not null |
Назва замовника |
Список полів таблиці-довідника „Форми контролю” (FK):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_fk |
Integer |
Primary key |
Код форми контролю |
|
2 |
Nazva_ fk |
Varchar (10) |
Not null |
Назва форми контролю |
Список полів таблиці-довідника „Дисципліни” (DISCIPL):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_discipl |
Integer |
Primary key |
Код дисципліни |
|
2 |
Nazva_ discipl |
Varchar (60) |
Not null |
Назва дисципліни |
Список полів таблиці-довідника „Факультети” (FAKULT):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_fakult |
Integer |
Primary key |
Код факультету |
|
2 |
Nazva_ fakult |
Varchar (40) |
Not null |
Назва факультету |
Список полів таблиці-довідника „Спеціальності” (SPEZIAL):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_spezial |
Integer |
Primary key |
Код спеціальності |
|
2 |
Nazva_ spezial |
Varchar (30) |
Not null |
Назва спеціальності |
Список полів таблиці-довідника „Викладачі” (VYKLAD):
|
№ п/п |
Назва поля |
Тип поля |
Властивість |
Розшифровка |
|
1 |
Kod_vyklad |
Integer |
Primary key |
Код викладача |
|
2 |
Prizv |
Varchar (20) |
Not null |
Прізвище викладача |
|
3 |
Ima |
Varchar (20) |
Not null |
Імя викладача |
|
4 |
Pob |
Varchar (20) |
Not null |
По-батькові викладача |
Рис. 14.5 - Таблиці бази даних „Навчальний процес”
Фізичне проектування бази даних.
На етапі фізичного проектування бази даних виконується вибір ефективного розміщення бази даних на зовнішніх носіях для забезпечення найбільш ефективної роботи додатків бази даних.
Основні проблеми, зв’язані з фізичним збереженням даних, викликані повільним доступом і пошуком, а також низькою швидкістю передачі. Тому головною метою підвищення продуктивності системи з цієї точки зору є мінімізація кількості дискових операцій введення-виведення даних.
Для збереження даних можуть використовуватися різноманітні структури, які мають різну продуктивність. Але ідеального способу зберігання даних не існує. Тому СУБД повинна містити декілька структур зберігання даних для різних задач і части системи, а також передбачати можливість зміни способів збереження в залежності від вимог до продуктивності системи.
Створення таблиць бази даних „Навчальний процес” засобами мови SQL.
Після створення бази даних необхідно створити таблиці. Таблиці створюються командою CREATE TABLE (див.розділ 6.4). Ця команда створює пусту таблицю (структуру таблиці), яка не містить записів. Нагадаємо, що записи до таблиці додаються командою INSERT. В команді CREATE TABLE задається ім’я таблиці та опис набору імен полів, які вказуються у відповідному порядку. Крім того, цією командою визначаються типи даних і розміри полів таблиці. Значення аргументу розміру залежить від типу даних. Якщо його не вказати, то СУБД призначить значення автоматично. Для числових полів це не важливо, а для даних типу CHAR потрібно обов’язково вказати розмір. За замовчуванням аргумент розміру дорівнює одиниці, а це означає, що поле може містити тільки один символ.
Наведемо приклад команди, яка створить структуру таблиці Облікові дані студентів:
create table student
(kod_st smallint not null primary key,
prizv varchar(20) not null,
ima varchar(15) not null,
pob varchar(15) not null,
data_nar datetime not null,
data_vst datetime not null,
kod_mova smallint not null,
kod_zamov smallint not null,
kod_pilgy smallint null,
kod_grupa smallint not null)
У цій команді CREATE TABLE використовується обмеження NOT NULL для запобігання попадання в поле нульових значень. Якщо при створенні таблиці обмеження не вказується, то SQL вважає, що нульові значення дозволені. Очевидно, що первинні ключі таблиці не повинні бути пустими, оскільки це буде порушувати їх функціональні можливості.
З допомогою PRIMARY KEY можна обмежувати таблицю або окремі її стовпці. Найкраще задавати обмеження PRIMARY KEY (первинний ключ) для поля, яке утворює унікальний ідентифікатор рядка. Первинним ключем таблиці Облікові дані студентів є поле kod_st.
Ці та інші обмеження розширюють можливості роботи з даними, які вводяться в таблицю. Коли створюється таблиця або змінюється її структура можна встановлювати обмеження на значення, які можуть бути введені в поля. Якщо це зроблено, SQL не буде дозволяти вводити значення, які порушують задані критерії. Існує два типи обмежень – обмеження поля (атрибуту), обмеження таблиці (відношення). Різниця між ними полягає в тому, що обмеження поля застосовується тільки до певного поля, а обмеження таблиці – до груп з декількох полів. Обмеження поля поміщається в кінець фрагмента команди після задання імені і типу даних. Обмеження таблиці поміщається в кінці команди після оголошення всіх полів. Наприклад, команда створення таблиці Паспортні дані матиме наступний вигляд:
createtablepasport
(kod_st smallint foreign key (kod_st) references student (kod_st),
seria varchar(7) not null,
nomer varchar(6) not null,
kum_vud varchar(30) not null,
kolu_vud datetime not null,
ident_kod varchar(10) not null,
unique (nomer, ident_kod)
Як вже було зазначено вище, для обмеження цілісності PRIMARY KEY автоматично гарантує унікальність значень. Але в кожній таблиці може бути лише один первинний ключ. Якщо ж необхідно додатково забезпечити унікальність значень ще в одному або більше стовпцях окрім первинного ключа, то необхідно використовувати обмеження цілісності UNIQUE. У таблиці Паспортні дані поля nomer, ident_kod оголошено унікальними з допомогою атрибута UNIQUE.
Крім цього, у даній таблиці використовується обмеження FOREIGN KEY (зовнішній ключ), яке забезпечуєзв’язок цієї таблиці (залежної) з головною таблицею Облікові дані студентів. Стовпці, які входять у зовнішній ключ, можуть посилатися тільки на стовпці первинного ключа або стовпці з обмеженням UNIQUE головної таблиці. Зовнішній ключ забезпечує цілісність даних двох таблиць. А саме, в залежну таблицю не можна вставити рядок, якщо зовнішній ключ не має відповідного значення в головній таблиці, а з головної таблиці не можна видалити рядок, якщо значення первинного ключа використовується в залежній таблиці.
В SQL також можна використовувати обмеження CHECK, яке задає діапазон можливих значень для стовпця. В основі обмеження цілісності CHECK лежить перевірка логічного виразу, який знаходить значення TRUE (істина) або значення FALSE (хибно). Якщо значення виразу – TRUE, то обмеження цілісності виконується і операція зміни чи вставки даних дозволяється. Якщо ж значення виразу – FALSE, то операція зміни чи вставки даних відміняється.
Наприклад, для забезпечення правильності задання значення стовпця в таблиці Навчальні плани (воно повинно знаходитися в діапазоні від 1 до 10) можна використовувати наступний логічний вираз:
((semestr>=1) OR (semestr<=10))
Обмеження цілісності на рівні поля буде виглядати так:
semestr integer not null check ((semestr>=1) OR (semestr<=10))
Використання бази даних „Навчальний процес” засобами SQL/
Метою будь-якої бази даних є введення, зміна, видалення і вибірка даних. Основним інструментом вибірки даних в мові SQL є команда SELECT. Розглянемо, як з допомогою цієї команди можна отримати доступ до даних, представлених в таблицях бази даних „Навчальний процес”.
Нехай необхідно сформувати список студентів-пільговиків. Це можна зробити з допомогою наступної команди:
select student.prizv, student.ima, student.pob, pilgy.nazva_pilgy
from student, pilgy
where student.kod_ pilgy is not nulland
student.kod_ pilgy = pilgy.kod_pilgy
Для формування списку студентів групи 202-БС, які навчаються на комерційній основі, необхідно виконати команду:
select student.prizv, student.ima
from student, zamov, grup
where student.kod_ zamov = zamov.kod_zamov and
student. kod_ grupa = grup.kod_grupa and
zamov.nazva_zamov = „Комерційна основа” and
grup. nazva _grupa = „202-БС”
Запити можуть керувати іншими запитами. Це робиться шляхом вміщення запиту всередину умови іншого запиту. Зазвичай, внутрішній запит генерує значення, яке перевіряється в умові зовнішнього запиту, яка визначає правильне воно чи ні. Наприклад, нам відоме прізвище студента, але нам потрібен його код для отримання даних з таблиці Успішність:
select usp.*
from usp
where kod_ st = (
select kod_ st
from student
where prizv = „Білан”
)
Вибрати з бази даних студентів, які отримали під час сесії незадовільну оцінку, можна з допомогою запиту:
select prizv, ima
from student
where kod_ st = (
select kod_ st
from usp
where ocinka = 2
)
Такий запит повертає список студентів, у якому можуть повторюватися прізвища та імена, оскільки студент під час сесії може отримати декілька негативних оцінок. Щоб уникнути цього запит слід доповнити описувачем DISTINCT.
Для того, щоб сформувати відомість рейтингу студентів, можна скористатися таким запитом:
select student.prizv, usp.avg(rating)
from student, usp
where student.kod_st = usp. kod_st
group by kod_st
order by usp.rating desc
Щоб вибрати з бази даних студента з найвищим рейтингом, потрібно виконати наступний запит:
select student.prizv, student.ima, usp.avg(rating)
from student, usp
where student.kod_st = usp. kod_st
group by kod_st
order by usp.rating desc
Аналогічно можна створити запити для формування екзаменаційної чи залікової відомості з конкретної дисципліни.
Список літератури
1. Бекаревич Ю. Б. Самоучитель Access 2010 / Ю. Б. Бекаревич, Н.В.Пушкинаю – СПб.:БХВ-Петербург, 2011. – 432 с.
2. Гурвиц Г. А. Microsoft Accecc 2010. Разработка приложений на реальном примере [Текст] / Г. А. Гурвиц. – СПб.: БХВ-Петербург, 2010. – 496 с.
3. Диго С. М. Базы данных: проектирование и использование [Текст]: учебник / С. М. Диго. – М.: Финансы и статистика, 2005. – 592 с.
4. Заверач М. М. Бази даних. Інформаційні системи [Текст]: навч. посіб. / М. М. Заверач, В. В. Третько. Хмельницький: ХНУ, 2007, - 303 с.
5. Золотова С. И. Практикум по Access. - М: Финансы и статистика / С. И. Золотова, 2008. – 144 с.
6. Кренке Д.Теория и практика построения баз данных [Текст] / Д. Кренке. – СПб.: Питер, 2005. – 859 с.
7. Марков А. С. Базы данных. Введение в теорию и методологию [Текст]: учебник / А. С. Марков, К. Ю. Лисовский. – М.: Финансы и статистика, 2003. – 512 с.
8. Проектирование баз данных. СУБД Microsoft Access / Учебное пособие // Н. Н. Гринченко, Е. В. Гусев, Н. П. Макаров. – М.: Горячая Линия – Телеком, 2004. – 240 с.
9. Фуфаев Э. В. Базы данных [Текст]: учебн. пособ. / Э. В. Фуфаев, Д. Э. Фуфаев. - М.: Академия, 2005. – 320 с.
10. Харрингтон Д. Разработка баз данных [Текст] / Д. Харрингтон. – М.: ДМК Пресс, 2005. – 272 с.
З повагою ІЦ "KURSOVIKS"!