








Матеріали до курсу Основи наукових досліджень, НТУУ КПІ
« Назад
Національний технічний університет України"Київський політехнічний інститут"
Матеріали до курсу Основи наукових дослідженьдля магістрів денної форми навчання
Київ - 2016 ЗМІСТ1. Загальні поняття. 4 1.1. Що таке наука. 4 2. Системний підхід. 11 3. Статистичні методи. 18 3.1. Шкали вимірювань. 18 3.2. Нечіткі обчислення. 20 3.3. Характеристики випадкової величини. 23 3.4. Перевірка статистичних гіпотез. 26 3.4. Загальна схема перевірки гіпотез про центри розподілу. 30 4. Моделювання. 36 5. Оптимізація. 41 5.1. Однокритеріальна оптимізація. 41 5.1.1. Загальна постановка. 41 5.1.2. Критерії ефективності 41 5.1.3. Оптимізація при наявності ризику. 41 5.1.4. Оптимальність при наявності невизначеності 42 5.1.5. Проблеми оптимізації. 42 5.2. Багатокритеріальна оптимізація. 42 5.2.1. Методи розв’язання багатокритеріальних задач. 42 5.2.2. Введення метрики в просторі цільових функцій. 43 5.2.3. Проблема визначення вагових коефіцієнтів. 45 5.3. Інші методи оптимізації 47 5.3.1. Динамічне програмування. 47 5.3.2. Нелінійне програмування. 51 5.3.3. Стохастичне програмування. 51 5.3.4. Стійке керування. 53 Практичні заняття. 55 1. Демонстрація необхідності планування експерименту. 55 1.1. Підвищення точності оцінок. 55 1.1.1. Традиційна схема зважування трьох об’єктів приведена в табл.. 1. 55 1.1.2. Ефективна схема зважування з плануванням експерименту. 55 1.1.3. Схема повного факторного експерименту. 56 1.1.4. Схема з дублюванням експериментів. 56 1.2. Забезпечення стійкості оцінок. 57 1.3. Забезпечення правильності визначення структури. 59 2. Регресійний аналіз. 73 1.2.2. Формалізація задачі 73 1.2.3. Аналіз и структурування об’єкту дослідження. 77 2.2. Побудова математичних моделей за експериментальними даними. 80 3. Регресійний аналіз. 86 3.1. Попередній аналіз результатів експерименту. 86 3.2. Перетворення даних. 88 3.3. Побудова коефіцієнтів математичної моделі і їх статистичних характеристик 92 3.4. Аналіз якості моделі 95 1. Загальні поняття1.1. Що таке наукаНаука – це шлях пізнання і оволодіння. Три шляхи пізнання (оволодіння навколишнім середовищем): - Науковий (об’єктивний); - Мистецький (суб’єктивний); - Містичний або релігійний (віра, інсайт, прозріння). Наполеон і Лаплас, Пелевін. В чистому вигляді ні один не існує. Наукові знання. Наукова істина. Розвиток і закономірності. Теоретичне знання, парадигми, теорії Особливості наукового знання. Наука відрізняється від звичайного знання тим, що є не просто сукупністю відомостей, а є системою знань. Ця система постійно змінюється. Мірилом істинності наукових знань є практична діяльність. Наукові істини в основному не є абсолютними. Істина – це процес. Процес наукового пізнання і наукові революції. Загальна схема розвитку науки. 1. Первісне накопичення фактів. 2. Формування понять, законів. 3. Створення теорій. 4. Поява парадоксів і спроба їх пояснювати спеціально кожен. 5. Зміна парадигми, з якою зв’язані засоби опису та аналізу. 6. Формування нових теорій. Сучасна парадигма: Світ єдиний (системний підхід) і недерміністичний (ймовірністний, хаос). В процесі розвитку кожна наука все більше математизується і теоретизується. Розвиток математизації (не обов’язково чисельної) та створення теорії, що пояснює і дозволяє формувати нові знання. Теорії дають рекомендації для практики, чи для напрямку розвитку науки. Місце математики (формалізації, моделі) З якогось моменту створення теоретичного знання продовжується, але рекомендації для практики перестають з’являтися. Наука продовжує викладатися, створюються теоретичні знання, але вимоги практики приводять до створення на її базі нової науки. (Геометрія – геодезія, картографія; теорія ймовірностей –математична статистика – прикладна статистика). Спеціалізація і інтеграція. Спеціалізація по проблемі. Логістична крива (кількісні зміни і якісні переходи). Методологія – це концептуальний виклад мети, змісту, методів дослідження, які забезпечують отримання максимально об’єктивної, точної систематизованої інформації про процеси та явища. Функції методології. 1. визначення способів здобуття наукових знань; 2. визначає шлях, на якому досягається певна науково-дослідницька мета. 3. забезпечує всебічність інформації щодо явища чи процесу, що досліджується; 4. допомагає введення нової інформації до наукових фактів та теорій; 5. забезпечує уточнення, систематизацію термінів і понять. Методика – сукупність прийомів дослідження включаючи техніку і операції х фактичним матеріалом. Фундаментальна, або філософська методологія. Визначає загальну стратегію принципів пізнання особливостей явищ, процесів. Сучасна – Діалектичний метод. Він дає змогу обґрунтувати причинно-наслідкові зв’язки, процеси диференціації та інтеграції, постійну суперечність між сутністю і явищем, змістом і формою, об’єктивність в оцінюванні дійсності. Досвід і факти є джерелом, основою пізнання дійсності, а практика – критерієм дійсності. Функції. 1. Виявлення смислу наукової діяльності та її взаємозв’язки з іншими сферами діяльності, тобто розглядає науку стосовно практики, суспільства, культури. 2. Завдання вдосконалення і оптимізації наукової діяльності. Загальнонаукова. - Історичний підхід. - Системний підхід. - Моделювання. - Термінологічний аналіз Визначення основних понять. Знання – це ідеальне (у свідомості людини) відтворення узагальнених уявлень про зв’язки об’єктивної реальності яке перевірене практикою. Пізнання – процес руху людської думки від незнання до знання. Це взаємодія об’єкта та суб’єкта результатом якого є нове знання про світ. Діалектика процесу пізнання в протиріччі між обмеженістю знань та нескінченною складністю об’єктивної дійсності. Спонукальною причиною пізнання є проблема, яка ставиться практичною діяльністю. Проблема. Це деяка невідповідність між бажаним і наявним, яке точно не визначено по цілі, структурі тощо. Формулювання проблеми фактично включає в себе шляхи розв’язку. Наукове дослідження є цілеспрямованим пізнанням, результати якого виступають в вигляді системи понять, законів та теорій. Наукове спостереження – цілеспрямоване та організоване сприйняття предметів та явищ навколишнього світу. Воно вимагає наявності певної ідеї та конкретизації умов спостереження. Властивості наукового спостереження. Інтерсуб’єктивність – результати не повинні залежати від особистості суб’єкта спостереження. Але інтерсуб’єктивність не означає об’єктивність, оскільки можливі помилки, ілюзії. Прилади теж цього не гарантують. Об’єктивність – результати піддаються перевірці в процесі практичної діяльності. Безпосередні та непрямі спостереження. З розвитком науки все більшу долю займають непрямі спостереження, в яких спостерігається не сам предмет, а його взаємодія з іншими предметами і явищами. В цих випадках спостереження обов’язково повинно опиратися на деяку гіпотезу чи теорію, що встановлює зв’язок між явищем, яке спостерігається і тим, що не спостерігається. Дані в науці є результатом дослідження. 1. Вони повинні бути очищені від суб’єктивності. 2. Даними є не відчуття і сприйняття, а результат їх раціональної обробки, що є синтезом чуттєвого сприйняття та теоретичних уявлень. 3. Дані обробляються як з точки зору відповідної галузі науки, так статистичними методами, стандартизуються. Функції наукового спостереження. 1. Забезпечення емпіричною інформацією для постановки проблем та висування гіпотез. 2. Перевірка гіпотез, які не перевіряються експериментально. 3. Співставлення результатів теоретичного дослідження, його адекватність. Чим відрізняється експеримент від спостереження; різний зміст цього терміну в різних науках. Функції наукового експерименту. 1. Перевірка гіпотез. 2. Уточнення при формуванні початкових допущень. 3. Отримання емпіричних залежностей. Гіпотези з’являються як з емпірики так і з теоретичного знання. Етапи пошуку закономірностей. 1. Спостереження. 2. Класифікація та аналіз як основа гіпотези та теорії. 3. Розвиток гіпотези та теорії для прогнозу нових результатів. 4. Спостереження та експеримент для підтвердження та розвитку теорії і т.д. і т.д. Планування експерименту взагалі і в особливості. Анекдот з феном. Досліди по виявленню електромагнетизму. Едісон матеріал лампи. Менделєєв – бездимний порох. Шкали вимірювання. Наукова ідея – інтуїтивне пояснення явища без проміжної аргументації і без усвідомлення всієї сукупності зв’язків, на основі яких робити висновок. Базується на наявних знаннях, але повинна виявляти нові закономірності. Гіпотеза – наукове припущення, висунуте для пояснення явищ чи процесів. Використовується для цілеспрямованого збору і групування наукових фактів. При узгодженні може перетворюватися в закон. Поняття (термін) – абстраговане відбиття суттєвих і необхідних ознак предметів і явищ. (+упаковка смислу). При дослідженнях, де перетинаються спеціалісти різних наук необхідно скласти список термінів з розшифруванням. Термінологія (згортка понять, встановлення відповідності що терміни означають приклади котли, меблі) Розкриття змісту поняття є його визначенням. Визначення поняття повинно: - вказувати на найближче родове поняття; - вказувати чим відрізняється дане поняття від інших. Закон – внутрішній суттєвий зв’язок явищ. Початкові закони і узагальнення отримують за допомогою індуктивної логіки. Такі абстракції, як поняття і закони, відображають окремі сторони явищ, але не дають цілісної картини. Теорія Для побудови теорій використовують дво основних способи. 1. Гіпотетико-дедуктивний. Це ієрархія гіпотез, логічна сила і узагальненість яких збільшується по мірі віддалення від емпіричного базису. Він приводить в єдину систему існуючі знання і встановлює логічні зв’язки між ними. 2. Аксіоматичний. Встановлюється системи аксіом. З неї отримують всі інші результати. Згідно з другою теоремою Геделя неможливо створити одночасно несуперечливу і повну систему аксіом. Наука (конкретна) є сукупністю теорій. Теорія – система ідей, поглядів, положень, законів, що описують явище чи процес. Це форма синтетичного знання. В його межах окремі поняття, гіпотези втрачають свою самостійність і перетворюються на елементи цілісної системи. Вона (теорія) повинна: - Бути адекватною описуваному явищу (процесу); - Бути повним описом явища (процесу); - Давати можливість замінювати експериментальні результати теоретичними; - Пояснювати взаємозв’язки між компонентами; - Бути внутрішньо несуперечливою. Теорію створюють, використовуючи: - Наукові факти; - Логічний аналіз; - Математичні засоби. Теорія повинна не тільки пояснювати існуючі факти, а й дозволяти прогнозувати нові результати. Теорії виникають тільки на певному етапі розвитку науки. Спочатку в результаті наукових досліджень отримують наукові факти, поняття, закони. Носій знань. Науковий обмін. Науковий колектив. Носій знань – вчений. Форми обміну та їх ефективність. Невидимий колектив. 2. Системний підхідКомпьютерная техника развивает определенную разновидность определенную разновидность мировосприятия – кругозор человека в туннеле, у которого вместо мысли одни статистические показатели, собранная информация, цифры. У специалистов такого рода недоразвита способность к мало-мальски стоящим оценочным суждениям и сверхразвита способность думать цифрами. Чтобы дать обобщающую оценку, нужно обладать видением системы в целом, уметь последовательно развивать мысль и вникать в глубинную суть явлений. Цифровые оценки достигаются куда проще и, даже если они ошибочны, все равно впечатляют, поскольку предстают как результат работы, проделанной с применением сложного современного оборудования. Питер Лоуренс Дж. Принцип Питера Світ єдиний і недерміністичний. Системою називається сукупність елементів з позитивною енергією зв`язку і/або позитивною кореляцією руху. Формальними ознаками системи є: - наявність певної множини взаємозв`язаних елементів; - вказана множина є єдиним цілим; - дана множина має мету, яка характерна саме для цієї множини елементів, а не для якої-небудь іншої їх комбінації.(пасажири літака чи десантники в літаку) Системи розділяють на відкриті, в яких є обмін енергією, речовиною чи інформацією з навколишнім середовищем та закриті, в яких такого обміну немає. Практично, закриті системи є деякою абстракцією, чи штучно створені. Будь-яка система існує і взаємодіє з певним навколишнім середовищем. Це середовище іноді називають надсистемою. Фактори дії середовища на систему називають вхідними або екзогенними. Фактори дії системи на середовище – вихідні, або ендогенні. Основними властивостями системи є: - цілісність –всі частини системи служать загальній меті, вилучення підмножини елементів приводить до втрати цілісності і знищення системи: - емерджентніть – система має властивості, яких немає в жодного з елементів, що її складають. Висновки з властивостей системи. - При вивченні система повинна розглядатися як єдине ціле. - Неможливо вивчити системи, вивчивши окремо її складові частини. Система – це не сума елементів, що її складають. Взаємодії створюють нові властивості. Бінарні гази, взаємодія фармпрепаратів, сліпці, що вивчали слона, колектив. Мета системи (енергокатастрофи США, Великобританія, Італія; Система охорони здоров’я Франція. Системні кризи в суспільстві.) Системний підхід – це вивчення системи як одного цілого. При вивченні: 1. Цілі системи. 2. Функції. 3. Структура. Діаграма Ісікава для побудови системи цілей. Мета системи – це “бажаний” стан виходів (чи множина станів виходів). Функція системи – це дії системи, які приводять до зміни її стану. Виконання системою своїх функцій називається функціонуванням. Функціонування – це еволюційний перехід системи із одного стану в інший. Так, наприклад, функцією виробничої системи є виготовлення певної продукції шляхом перетворенні вхідних матеріальних та енергетичних потоків. Для кожної системи характерним є наявність певної структури – сукупності зв`язків та відношень між її елементами. Структура – це внутрішня впорядкованість, погодженість взаємодії окремих елементів системи. При цьому існує певна динамічна стійкість просторово-часових зв’язків елементів структури системи. Елемент системи – це частина системи, яка виходячи з функції та цілей даної системи вважається неподільною. Зміна системою своєї структури називається біфуркацією. Поблизу точки біфуркації малі впливи можуть привести до великих змін стану системи та її динаміки. Складністю системи називають розмірність простору структури. Складна система характеризується множиною неоднорідних структур і множиною зв’язків між ними. Число її станів велике і опис викликає труднощі. - примітивні, для яких єдиними біфуркаціями є народження і смерть; - аналітичні, які проходять в своєму існування скінчений рід біфуркацій; - хаотичні, в котрих в кожен момент змінюється хоча б один структурний фактор. Системи відкриті, нелінійні, нестійкі. Фазовий простір– це простір, утворений множиною показників, які повністю характеризиють стан системи в будь-який момент її існування. Ат трактор – траєкторія руху системи в фазовому просторі. В процесі еволюції однієї і тієї ж системи (чи з різних точок зору) поведінка системи може описуватися детерміністично, статистично, теорією хаосу. Саморегуляція внутрішні перетворення структури, які направлені на збереження працездатності процесів. Цілісність системи обумовлена взаємозв’язком процесів, що в ній відбуваються. При взаємодії елементів можливі наступні процеси. 1. Перетворення (зміна складу, структури і властивостей) речовини; 2. Перетворення (взаємопереходи, трансформація) енергії; 3. Перетворення (обробка, перетворення форми представлення) інформації; 4. Зберігання (затримка по доступу в часі) речовини. 5. Акумуляція (накопичення) енергії. 6. Зберігання (запамятовування ) інформації; 7. Транспортування (переміщення) речовини. 8. Передача енергії; 9. Передача (обмін) інформацією. Більш ефективними та життєздатними є ті системи, в яких розширення функціональних можливостей елементів випереджає зростання складності системи. (Демократія – монархія в різних суспільствах). При створенні: 1. Дерево цілей системи.. 2. Дерево функцій системи. 3. Дерево протиріч системи. 4. Структури системи на основі функціональних модулів. 5. Структури системи на основі конструктивних модулів. Аналіз, синтез, “чорний ящик” Принципи ускладнення поведінки систем 1. матеріально-енергетичного балансу (на основе законів збереження); 2. гомеостазиса (на основі зворотніх звязків); 3. вибору розв’язку (на основі індуктивної поведінки; 4. перспективної активності або потрібного майбутнього (преадаптація, випереджуюча реакція); 5. рефлексії (випереджуюче відображення). Стійкість. Прості системи мають пасивні форми стійкості: міцність, збалансованість, гомеостази (повернення в стан рівноваги при виведенні з нього) Для складних – активні: надійність (збереження структури системи незважаючи на загибель окремих елементів за допомогою заміни чи дублювання) і живучість (активне подавлення шкідливих факторів). Принципи побудови систем 1. Цілісність. 2. Структурність (можливість опису системи через встановлення її структури). 3. Ієрархічність (кожен елемент системи може розглядатись як с самостійна система, а досліджувана система як елемент іншої системи). 4. Взаємозв’язок елементів всередині системи, а також системи та навколишнього середовища. 5. Множинність опису системи (для дослідження системи необхідно будувати множину різних моделей, кожна з яких описує тільки окремий її аспект). Катастрофа. Зміна характеру зв’язків і поведінки системи називається біфуркацією.
Рис. 1 - Біфуркація і катастрофи типу складки Ознаки катастрофи. 1. Аномальна дисперсія (збільшення розмаху коливань величин, що характеризують систему). 2. Можливість існування більш ніж однієї траєкторії стійкого розвитку чи рівноваги; стрибкоподібна зміна значень характеристик; великі зміни характеристик при малих вхідних діях; проява гістерезисна (труднощі при поверненні системи до характеристик попереднього стану). 3. Різниця в реакції на одні і ті ж вхідні дії при однакових умовах; сповільнення затухання коливань характеристик; збільшення частоти коливань. Приклад катастрофи на психологічних тестах (рис.). Якщо розглядати малюнки по горизонталі, то кожен з них відрізняється від свого сусіда незначними деталями. В деякій зоні малюнки можуть бути інтерпретовані двояко: і як чоловіче обличчя і як сидяча дівчина (біфуркація). Але при послідовному пред’явлені їх спостерігачу в деякий момент він ідентифікує їх однозначно (катастрофа: обличчя–дівчина). Конкретний малюнок переходу залежить від того з якого боку починається показ. Зона невизначеності відмічена “дзьобом”. Рис. 2 - Приклад катастрофи на психологічних тестах 3. Статистичні методи1. Що таке статистичні методи. Види (математична, прикладна, непараметрична, робастна, аналіз даних). 2. Шкали вимірювань. 3. Класи статистичних задач. 4. Перевірка гіпотез. Загальні поняття та вибір методів. 5. Гіпотези про параметри положення та розсіяння. 6. Визначення наявності залежності між змінними. 7. Методи класифікації. 8. Зниження розмірності. 9. Побудова моделей за емпіричними даними (чорний ящик, планування експерименту, регресійний аналіз). 10. Моделі марківських ланцюгів. 3.1. Шкали вимірюваньИзмеряй все доступное измерению и делай недоступное измерению доступным. Галілео Галілей Обробка статистичними методами можлива лише для тієї інформації, яку можна виміряти. В зв’язку з цим розглянемо, які можливі шкали вимірювань. В залежності від шкали, в якій вимірюються наші дані, можливе використання різних статистичних методів для розв`язання однієї і тієї ж задачі. Існують наступні шкали вимірювань: - шкала класифікації (найменувань); - шкала порядку; - шкала інтервалів; - шкала відношень. Розглянемо особливості цих шкал. Шкала класифікації (найменувань, номінальна). Неможливі ніякі операції по порівнянню даних, окрім “дорівнює” та “не дорівнює”. Нумерація чи найменування служить тільки для ідентифікації об`єкту — номер будинку, номер на майці спортсмена тощо. Шкала порядку. Можливе порівняння об`єктів по величині (більше, менше, дорівнює). Інші операції неможливі. Прикладом може слугувати шкала твердості мінералів, в якій є ряд еталонних мінералів, сформований таким чином, що кожен наступний мінерал в ряду твердіший за попередній. Шкала інтервалів. В цій шкалі можливе не тільки порівняння по величині, але також і визначення наскільки більше (тобто можливі операції додавання та віднімання). Прикладом можуть бути шкали вимірювань температури (Цельсія, Кельвіна, Фаренгейта, Реомюра). Шкала відношень. В цій шкалі можливі всі операції (порівняння, додавання, віднімання, множення та ділення), тобто можливо поставити питання у скільки разів. Приклади — вага, довжина тощо. В цих випадках існує природна точка відліку (початок координат, нуль). Потрібно відмітити, що в процесі розвитку відповідних наук та засобів вимірювань можливий перехід від однієї шкали до іншої, більш досконалої. Так, наприклад, перші термометри вимірювали температуру в шкалі порядку (помірно, тепло, гаряче і т.д.). Іноді кажуть також про дискретні та неперервні шкали вимірювань. В загальному випадку до дискретних відносіть шкали класифікації та порядку. В цих шкалах не існує проміжних значень (наприклад – номер будинку 53,4 або твердість 2,5) Таблиця 1. Можливі операції в різних шкалах вимірювань
3.2. Нечіткі обчисленняНечітка логіка стала розвитком можливих шкал вимірювання. Вона дає можливість працювати з так званими лінгвістичними змінними. Ними називають вислови, які використовуються для оцінок деяких характеристик. Наприклад, молодий, старий або великий, дуже великий, маленький тощо. Використанні апарата нечіткої логіки дозволяє обробляти такі вимірювання, що розширює можливості аналізу даних і дозволяє більш повно та точно враховувати інформацію, що надається експертами. Розглянемо приклад для отримання числового опису поняття “висока температура” в медицині. Ми згодні, що 37 це ще не висока температура, а 38 – вже висока. В такому разі у відповідність 37о ставимо 0, що означає ” 37о точно не висока температура”, а у відповідність 38о ставимо 1, що означає “38о – висока температура”. Побудуємо функцію приналежності значення температура множині “висока температура” (див. рис.1). Із нього видно, що для температури менше 37о значення цієї функції дорівнює 0, а для температури більше 38о – 1. В інтервалі температур (37о, 38о) ступінь приналежності до множини “висока температура” визначається відповідним значенням У. Так, для 37,5о – це 0,5. Лінія, що описує характеристичну функцію зовсім не обов’язково має бути прямою лінією, вона може бути любою гладкою функцією. Нечіткі обчислення використовуються в тому випадку, коли необхідно обробити (представити в математичній формі) експертні знання, які сформульовані в вигляді словесних (лінгвістичних) виразів. Рис. 3 - Характеристична функція визначення «висока температура» Для роботи з такими даними використовуються модифікації логічних операцій, наприклад логічного множення і логічного додавання. Вони дозволяють обчислити результат виразу, який об’єднує вирази за допомогою операцій “І”, “АБО”. Наприклад, “результатом технологічного процесу буде брак, якщо температура буде висока, або час витримки великий”. Таблиця 2 - Виконання деяких операцій нечіткої логіки
3.3. Характеристики випадкової величиниБогу всегда середина любезна, и меру чтит божество. Эсхілл. “Эвменіди” Средний человек в обществе то же, что центр тяжести в физическом теле; имея в виду эту центральную точку, мы приходим к пониманию всех явлений равновесия и движения. Адольф Кетле В статистиці при аналізі даних завжди існують наступні проблеми: 1. Скільки даних необхідно вибрати і як їх відбирати. 2. Правомочність поширення висновків, зроблених на основі вибіркових даних на всю генеральну сукупність. 3. Вибір оптимальних способів оцінювання. 4. Вибір способів узагальнення, класифікації та представлення даних. Кожним зі вказаних питань займаються різні розділи статистики і, відповідно, і різні люди. Дослідник же завжди повинен пам`ятати про ці проблеми, оскільки він відповідає за результати досліджень та зроблені висновки, що в багатьох випадках може впливати на матеріальне становище, здоров`я та навіть життя багатьох людей. Властивості оцінок параметрів Оцінки параметрів повинні відповідати наступним вимогам[1]: Незміщеність — означає, що при проведенні дуже великої кількості дослідів з вибірками однакового розміру середнє значення кожної вибірки наближається до істинного значення генеральної сукупності. Зміщеність зазвичай обумовлена наявністю систематичної похибки. Обґрунтованість — з ростом розміру вибірки оцінка повинна наближатися з ймовірністю, що прямує до 1, до значення відповідного параметра генеральної сукупності. Ефективність — вибрана оцінка для вибірок рівного обсягу повинна мати мінімальну дисперсію. При розробці оцінок, як правило, висувають деякі припущення. В зв`язку з цим оцінки відповідають приведеним вимогам (мають відповідні властивості) тільки при виконанні припущень. Про це необхідно пам`ятати при використанні оцінок. Для оцінювання параметрів використовуються різноманітні методи, особливе місце серед яких займає метод максимальної правдоподібності. Він використовується в тих випадках, коли відомий закон розподілу. Ідея його – оцінки мають бути рівні значенням, при яких вибірка має максимальну ймовірність появи. До характеристик одновимірного розподілу відносяться: 1. Міри положення (середнє, медіана, мода тощо). 2. Міри розсіяння (розмах, коефіцієнт варіації, дисперсія, середньоквадратичне відхилення). 3. Міри форми (асиметрія, ексцес, моменти третього та четвертого порядку). Властивості середнього (вибіркового) - Сума відхилень від середнього дорівнює 0. - Якщо всі значення вибірки збільшити чи зменшити, помножити чи поділити на одне і теж число, то середнє значення зміниться аналогічно. - Зі збільшенням числа вимірювань точність оцінки збільшується і вона наближається до відповідного значення генеральної сукупності, але тільки в тому випадку, якщо немає систематичних похибок і виміри незалежні. - Середнє суми двох вибірок дорівнює сумі їх середніх, якщо вибірки однакових розмірів (аналогічно для різниці) - Якщо ряд спостережень складається з К груп, то середнє арифметичне всього ряду дорівнює виваженій груповій середній, ваговими коефіцієнтами при цьому виступають обсяги груп[2] Декілька несподіваних зауважень Середнє зовсім не є типовим. Наприклад, середній прибуток ні в якому разі не є типовим для більшості країн. Середнє не співпадає з математичним сподіванням. За винятком випадку нормального розподілу арифметичне середнє навіть не є незміщеною оцінкою математичного сподівання з найменшою дисперсією. Більш того, навіть для нормального розподілу можна вказати оцінку, яка буде ближче до математичного сподівання, правда без деяких корисних властивостей середнього. Властивості медіани - Сума абсолютних величин відхилень варіантів від медіани, помножених на відповідні частоти є мінімальна, тобто менше, ніж від будь якої іншої величини[3] x – Me mx x – a mx."x"x На значення медіани не впливають зміни крайніх значень варіаційного ряду, якщо тільки менше медіани залишається меншим, а більше продовжує залишаться більшим[4]. Медіана є більш стійкою оцінкою міри положення у випадку наявності “викидів”. Властивості дисперсії - Дисперсія постійної величини дорівнює 0. - Якщо всі результати збільшити або зменшити на одне і то ж число, то дисперсія не зміниться. - Дисперсія суми і різниці випадкових величин дорівнює сумі дисперсій. - Якщо всі результати змінити в К разів то дисперсія зміниться в К2 раз[5]. - Корінь квадратний з дисперсії це середньоквадратичне відхилення — S. В англомовній літературі цей термін прийнято називати стандартною помилкою. Фактичний довірчий інтервал при одночасній оцінці кількох параметрів, буде менше, ніж задається загальноприйнятими формулами. 3.4. Перевірка статистичних гіпотезГипотеза может быть проверена, но никогда не может быть доказана. Л.Закс “Статистическое оценивание” Нулевая гипотеза – это род рассуждения, называемого reducio ad absurdum[6] и состоящего в опровержении выдвинутого утверждения путем показа его невероятности. Соломон Дайменд “Мир вероятности. Статистика в науке” Це гіпотези, які відносяться до виду чи значення окремих параметрів розподілу випадкової величини. Нехай f(X, — закон розподілу випадкової величини Х з деяким параметром. Тоді: H0 (нульова гіпотеза): H1 (альтернативна або конкуруюча гіпотеза). Помилка першого роду: — H0 відкидається, коли вона істинна. Помилка другого роду: — H0 приймається, коли істинна H1. Будь-які гіпотези перевіряють, висуваючи спочатку комплекс певних допущень про закон розподілу випадкової величини. Невиконання цих допущень робить висновки із перевірок по гіпотезі некоректними. Нульова гіпотеза відхиляється в тому випадку, коли ймовірність того, шо вона вірна виявляється нижче деякого рівня, який називається рівнем значущості. Таблица 3. Можливі ситуації при перевірці статистичних гіпотез
Тут a – ймовірність помилки першого роду або рівень значущості; (1–a) – довірча ймовірність; b – ймовірність помилки другого роду; (1–b) – потужність критерію. В технічних дослідженнях, як правило потужність критерію не розраховують. Можливе його значення враховують при виборі критерію. Це зв’язано з значними складностями при визначенні потужності в реальних дослідженнях. На його значення впливає велика кількість факторів і їх необхідно надати певні значення. Ситуація ускладнюється тим, що частина факторів залежить одна від одного. На величину потужності впливають a, b, кількість експериментів, варіабельність, виконання передумов та допущень критерію (відповідність прийнятої гіпотези реальному стану справ), фактичне значення параметру, який перевіряється.. Таблиця 4. Характер залежності потужності від інших показників (при умові, що інші не міняються)
Рис. 4 - Взаємозв’язок помилок 1-го и 2-го роду Нехай ліва крива відповідає статистиці нульової гіпотези, а права – альтернативної. Тоді площа під першою кривою зліва від вертикальної лінії відповідає ймовірності помилки першого роду, а площа під другою кривою зліва від вертикальної лінії – ймовірності помилки другого роду. Пересуваючи вертикальну лінію вправо для того, щоб зменшити помилку першого роду, ми тим самим збільшуємо помилку другого роду і зменшуємо потужність. На рис. Видно залежність потужності від числа дослідів і фактичного значення параметру, який перевіряється. Добре видно, що потужність збільшується зі зростанням розміру вибірки. Це можна інтерпретувати таким чином, що при малій різниці між параметрами, що порівнюються необхідно більше експериментів для впевненого прийняття рішення про наявність різниці між ними. З того ж малюнка видно, що в тому випадку, коли фактичне значення параметру, який перевіряється відрізняється від прийнятого в нульовій гіпотезі (Но: р ¹ 0,5), це приводить до збільшення помилки другого роду і зменшенню потужності. Крім того, залежність потужності від виконання деяких передумов може мати дискретний характер. Так відомо, що при використанні непараметричних критеріїв до даних, які мають нормальний закон розподілі непараметричні критерії мають меншу потужність, ніж відповідні параметричні.
Рис. 5 - Крива потужності для перевірки біноміальної гіпотези р=0,5 для різного числа дослідів Односторонні та двосторонні критерії В тому випадку, коли нульова гіпотеза сформульована в формі, використовується двосторонній критерій.
Рис. 6 - Приклад критичної області для двохстороннього критерію Якщо ж ми формулюємо нульову гіпотезу Если в виді або), то в цьому випадку використовується односторонній критерій.
Рис. 7 - Пример критической области для одностороннего критерия Односторонній критерій при інших однакових умовах має більшу потужність, ніж двохсторонній. Якщо нас цікавить тільки абсолютне значення деякого параметру, то використовується односторонній критерій, якщо і знак, то двосторонній. Розраховане р-значння Виходячи з вищевказаного зрозуміло, що саме розраховане р-значення в тому випадку, якщо воно мало (наприклад, менше 0,001) не несе достатньої інформації для правильних висновків. Адже воно розраховано, виходячи з правильності нульової гіпотези. Якщо ж нульова гіпотеза невірна, то це значення практично немає ніякого значення для інтерпретації. 3.4. Загальна схема перевірки гіпотез про центри розподілуТиповим використанням гіпотези про середні є ситуація, коли ми маємо дві вибірки випадкової величини. Перевірка гіпотези дозволяє відповісти на питання, чи є статистично значимою різниця між середніми цих вибірок. Іноді при перевірці цієї гіпотези може виникати протиріччя між інтуїтивним уявленням (середні сильно відрізняються) і висновками з перевірки гіпотези — середні відрізняються статистично не значимо. Це зв`язано з тим, що довірчий інтервал одного із середніх повністю включає в себе довірчий інтервал іншого середнього. Непараметричні критерії вибираються в тому випадку, коли шкали вимірювань нечислова (порядкова чи найменувань), або коли закон розподілу відмінний від нормального. Перевірити чи є закон розподілу нормальним можна за допомогою простої нестрогої перевірки. Якщо виконується умова то закон розподілу можна вважати нормальним. Деякі зауваження до перевірок середніх В тому випадку, коли вибірка формується не випадково, стандартні відхилення зменшуються, а різниця середніх значень збільшується. Таблиця 5. Вибір критерію для перевірки статистичної гіпотези про міри розсіяння та положення
Можливі парадокси при перевірці гіпотез про середні При перевірці гіпотез можливі наступні ситуації: Щоб прийняти рішення в таких ситуаціях існують спеціальні методи перевірки рівності між собою декількох середніх. Метод множинних порівнянь Шеффе Досить частою є ситуація, коли необхідно порівняти між собою не два значення середніх, а більше. Порівняння їх за допомогою дисперсійного аналізу дозволяє встановити чи можемо ми вважати їх рівними, чи ні. Але в тому випадку, коли вони не рівні, необхідно визначити, які середні рівні між собою, які ні. Використовувати попарні порівняння в цьому випадку не можна, так як виникають парадокси (див. вище). Крім того, фактичний рівень значущості буде набагато більше ніж встановлений експериментатором. Наприклад, коли ми маємо 5 вибірок, то загальна кількість можливих пар порівнянь k=5!/2!(5–2)!=10, тоді ймовірність отримати хоч один значимий результат при рівні значимості в кожному Р = (1 – (1 – 0,05)10 » 0,40. Призначення. Перевірка гіпотези про приналежність кількох середніх до однієї генеральної сукупності, або визначення груп середніх значень, що належать до однієї сукупності. Нульова гіпотеза. H0: Передумови. Дані повинні бути розподілені по нормальному закону і бути незалежними. Короткі теоретичні відомості. Контрастом називається лінійна комбінація середніх значень вибірок. Наприклад ми маємо 5 вибірок, середні значення яких Зрозуміло, що коефіцієнти Сi для першого випадку мають значення 1/2, 1/2, –1/3, –1/3, –1/3, а для другого 1, –1/4, –1/4, –1/4, –1/4. Якщо б ми бажали порівняти першу та четверту вибірки, то коефіцієнти С будуть мати значення 1, 0, 0, -1, 0. Таким чином, змінюючи С, можна перевірити будь-які комбінації пар вибірок Критеріальне значення розраховується по формулі Де внутрігрупова дисперсія Формування груп середніх за допомогою LSD-критерію (leastsignificantdifference) Виконується наступна послідовність дій. 1. Впорядкувати значення середніх по величині. 2. Для кожної пари, починаючи з першої, виконати перевірки значимості середніх. Для цього розраховується значення LSD. При рівних розмірах вибірок використовується формула: Якщо, розміри вибірок різні, то користуються формулою, по якій розраховується значення для кожної пара вибірок де tn-k,a – табличне значення критерію Стьюдента; – внутрішньо групова дисперсія; F1,n-k,a – табличне значення критерію Фішера; ni –кількість спостережень в кожній виборці (якщо вони однакового розміру); na и nb – кількість спостережень в вибірках, які перевіряються; k – кількість вибірок. Якщо різниця середніх значень сусідньої пари менше значення LSD, то ці середні вважаються однаковими, а відповідні вибірки об’єднуються в однорідну групу. Зауваження. При сумісному використання порівнянь по Шеффе і критерию LSD можлива поява уявних протиріч. Наприклад, середні значення вибірок, що входять в різні однорідні групи, не відрізняються значимо одне від одного. Справа в тому, що в однорідній вибірці зібрані вибірки, для сукупності середніх яких приймається гіпотеза про їх рівність. сукупності середніх которых принимается гипотеза об их равенстве. То ж, що деякі з них при попарному порівнянні можуть бути рівними середнім інших вибірок цьому ніяк не протирічить. 4. МоделюванняМодель це система, що може заміщати оригінал так, щоб вивчення системи давало нову інформацію про оригінал. Модель відтворює значущі властивості оригіналу. Моделювання це процес побудови та дослідження моделі. Процес моделювання включає наступні етапи: 1. постановка проблеми та формалізація задачі. 2. Побудова моделі. 3. Експериментальне дослідження моделі. 4. Перенесення результатів, отриманих на моделі, на оригінал. Модель як відображення світу. Відношення моделі і світу. Базовий тип моделі – імітаційна (об’єктно-орієнтована). Різні моделі одного і того ж процесу (історично і одно моментно). Обмеженість моделей. Зміна моделей в процесі розвитку науки (світло, сонячна система). Опис складного об’єкту сукупністю різних моделей (світло, людина). Ізоморфні відносно входів-виходів математичні моделі (різні). Приклад прогнозу. Базовий тип моделі – імітаційна (об’єктно-орієнтована). Моделі: фізичні і символічні. Фізичні: геометричної подібності і аналогові. Геометричної подібності: однієї ж природи, зміна розмірів. Структура і геометричні властивості оригіналу. Моделі будівель, кораблів, літаків. Басейни, аеродинамічні труби. Переваги: 1. Можливість заміщувати складні, дорогі системи, експерименти над якими проводити неможливо, або економічно невигідно. 2. Наочність отриманих результатів про структуру та функції реальної системи. 3. Достовірність результатів. Недоліки: 1. Для кожної системи потрібну будувати нову чи перебудовувати стару. 2. Погано пристосовані для вивчення динаміки. Обмеження їх, наприклад, міцність, бульб. + Стенди (космос, авіація, авто). Фрагменти (в кораблебудуванні). Аналогові. За допомогою фізичних процесів, що аналогічні іншим фізичним процесам, описуються такими ж математичними співвідношеннями, напр. диф. рівняннями, але мають іншу фізичну структуру. АВМ, логарифмічна лінійка (відрізки на шкалі аналоги цифр). (Гідро, електро-, АОМ). Символічні відображають структуру та функції оригіналу за допомогою символів та відношень між ними. Символические описывают структуру и функции оригинала с помощью символов и отношений между ними, выражающих определенные зависимости, присущие оригиналу. Математические модели (подмножество символических) уравнения, неравенства, функции, алгоритмы и пр.) Математические модели представляют собой систему математических и логических отношений описывающих структуру и функции реальной системы. Они отличаются по своей природе от оригинала. Исследование дешевле занимает меньше времени. Математичні моделі (рівняння, нерівності, матричне, графи, функції, алгоритми тощо) Відповідність моделі аналогові. Види аналогії (подібності) моделей) 1. Ізоморфізм. Взаємно-однозначна відповідність структур моделі та оригіналу. Діюча модель верстату. 2. Гомоморфізм. Кожному елементу моделі відповідає елемент оригіналу, але не навпаки. Відображаються лише основні властивості системи. Блок-схема як гомоморфна модель програми. Всякий ізоморфізм є гомоморфізм, але не навпаки. 3. Подібність відношень. Для моделі та оригіналу різної природи. Моделі – закономірність розвитку будь-якої науки. Важливість моделювання як практична так і пізнання, розвитку методів, формалізації. Емпіричні (всі закони емпір.) Спрощення; осн. закономірність. Клас. Моделей. Статичні, динамічні. Структурні і функціональні. Описові та оптимізаційні. Детерміністичні, стохастичні, з урахуванням невизначеності. Лін-нелін, загальна структура, період/непер. Часткова структура; неоднозначність. Пуанкаре про математику і природу. Простота (Птоломей–Копернік; Оккама) Можливість смислового аналізу Особливості комп’ютерних моделей. Обєктно-орієнтоване моделювання. Для проведення імітаційного моделювання необхідно побудувати об’єктно-орієнтовану модель системи. При створенні моделі, виходячи із цілей та функцій системи, створюється сукупність абстракцій, що дозволяють описати функціонування системи. Абстракція виділяє суттєві характеристики деякого об’єкту, що вирізняють його від інших, і таким чином визначає його концептуальні межі з точки зору спостерігача. Модель системи є сукупністю діаграм класів, об’єктів, взаємодій та переходів. Діаграма класів системи включає всі класи системи та відношення між ними. Діаграми станів та переходів та взаємодії і раніше широко використовувалися. Перші – це графи станів та переходів, що описують марківський ланцюг станів, а другі – технологічні діаграми. При моделюванні ООМ використовують наступні види абстракції. - Абстракція сутності. Об’єкт є моделлю деякої сутності з предметної області. - Абстракція поведінки. Об’єкт складається з сукупності операцій. Елементами абстракцій є класи. Клас фактично є класифікаційною одиницею. Класом можуть бути матеріальні предмети, процеси, інформаційні потоки та ін. Результатом роботи по класифікації та абстрагуванню повинна бути діаграма класів системи, яка описує властивості класів, їх функції та взаємодію. Цей процес відбувається послідовним уточненням і деталізацією абстракцій. Основні типи відношень – це відношення “узагальнення-спеціалізація”, “ціле-частина”. Відношення між класами (і об`єктами) можуть бути наступних типів: - Наслідування (позначається на схемах - Асоціація, або посилання (позначається - Агрегація, фізична або по посиланню (позначається - Використання (позначається Асоціація звичайно має форму обміну інформацією. При агрегації фізичній агрегований клас чи об’єкт є фізичною частиною іншого об’єкту (наприклад, крило ЛА), а при агрегації посиланням може існувати окремо (наприклад, ракета як вид змінного озброєння тощо). Потрібно сказати, що при достатньо довгій еволюції систем, які сильно залежать від зовнішнього середовища, результати часто наближаються до того вигляду, який може бути отриманий при оптимізації за допомогою системного підходу. Це зв’язано з тим, що з положень загальної теорії систем [?] система при еволюції змінює свою структуру таким чином, щоб найкращим чином відповідати умовам існування. При формуванні класів використовується принцип інкапсуляції, що дозволяє не деталізувати тих особливостей класів та об`єктів, які не потрібні при аналізі їх взаємодії. В класах необхідно визначити функції. Функції є описом взаємодії даного (об`єктів даного класу) класу з іншими класами (об`єктами). Так група обслуговування проводить перевірку та підготовку до польоту певних агрегатів ЛА (відповідно до своєї спеціалізації) і повідомляє про готовність (чи наявність несправностей). Інкапсуляція. Це процес відділення одне від одного елементів об’єкту, які визначають його поведінку і будову. Так для “клієнтів” ТЕЧ зовсім необов’язково знати її внутрішню організаційну будову. Означає наявність в класі двох частин: інтерфейсу та реалізації. В інтерфейсі зібрано все, що стосується взаємодії об’єкту з іншими об’єктами. Реалізація описує представлення абстракції та механізми досягнення бажаної поведінки. Вона приховує від інших об’єктів деталі, що не мають відношення до взаємодії. Інкапсуляція захищає від помилок. Модульність. Це властивість системи, яка може бути розкладена на внутрішні зв’язні, але слабко зв’язані між собою частини. В наших умовах це окремі підрозділи частини. Модель системи є сукупністю діаграм класів, об’єктів, взаємодій та переходів. Діаграма класів системи включає всі класи системи та відношення між ними. Діаграми станів та переходів та взаємодії і раніше широко використовувалися в авіаційній науці. Перші – це графи станів та переходів, що описують марківський ланцюг стану, а другі – технологічні діаграми. 5. ОптимізаціяЗадача в котрій рішення зводиться до визначення мінімуму або максимуму називається оптимізаційною задачею. Визначення мінімуму виконується за цільовою функцією (критерієм оптимальності). 5.1. Однокритеріальна оптимізація5.1.1. Загальна постановкаНехай існує множина елементів U, яка називається множиною допустимих елементів. Задана функція J, яка відображає множину U в множину дійсних чисел така функція називається функціонал). Задача: знайти Задача може не мати розв’язку. Оптимізація може бути безумовна та умовна. При постановці задачі умовної оптимізації крім цільової функції додатково задаються обмеження. Обмеження можуть бути накладені як на незалежні змінні так і на саму цільову функцію. Вид обмежень: обмеження виду нерівностей і обмеження виду рівнянь При розв’язанні задачі обмеження може бути враховане двома способами: 1. Обмеження включається безпосередньо в конструкцію критерію оптимальності і виконується безумовна оптимізація. 2. Виконується задача оптимізація з обмеження (лінійне або нелінійне програмування). 5.1.2. Критерії ефективності1. Область збіжності. 2. Швидкість збіжності. 3. Похибка. 5.1.3. Оптимізація при наявності ризикуY=F(X,Z). Z – випадковий вектор з відомим розподілом і його параметрами. Розв’язання виконується в один з наступних варіантів. 1. Виконується перехід до виразу Y=F(X,ZМ), де. ZМ=М(Z). В такому випадку досягається оптимальність в середньому з певною ймовірністю ризику. 2. Виконується перехід до задачі Y=М(F(X,Z)), яка розв’язується методами стохастичного програмування. 5.1.4. Оптимальність при наявності невизначеностіY=F(X,Z). Z – випадковий вектор з невідомим законом розподілу і його параметрами, або детермінований вектор з невідомими значеннями. Для розв’язання використовується принцип гарантованого результату. Виконується розв’язок модифікованої задачі 5.1.5. Проблеми оптимізаціїПогана обумовленість (проблема яружності). Пошук глобального екстремуму 5.2. Багатокритеріальна оптимізаціяLulla lex satis commodo omnibus est[7] Liv.,Hist.,XXXIV,3 5.2.1. Методи розв’язання багатокритеріальних задачПри розв`язанні реальних задач об`єкт звичайно описується не одним, а декількома показниками його функціонування чи якості. При оптимізації вимоги до них можуть бути достатньо суперечливими, тобто покращення одного показника веде до погіршення іншого. Існують наступні методи розв’язання багатокритеріальних задач. 1. Лінійна згортка критеріїв. 2. Використання контрольних (нормативних) показників 3. Редукція до одновимірної задачі шляхом приведення всіх показників крім одного до обмежень. 4. Введення метрики в просторі цільових функцій. 5. Компроміси по Парето. Побудова множини результатів, які неможливо покращити. 5.2.2. Введення метрики в просторі цільових функційВ зв`язку з цим виникає задача визначення деякої компромісної точки, яка повинна в певній мірі відповідати всім вимогам. Це така точка, що будь-яка інша буде гірша неї за всією сукупністю характеристик (компроміс по Парето). Як правило, результати по кожному окремому показнику якості для цієї окремої точку будуть гірші, чим у випадку однокритеріальної оптимізації по цьому параметру. Суть запропонованого підходу в тому, що кожному об`єкту ставиться у відповідність точка в багатовимірному просторі (точніше в М-вимірному, де М – кількість критеріїв якості), координатами яких є параметри, що його описують. Простір нормовано в одиничний гіперкуб таким чином, що по кожній координаті рух від 0 до 1 відповідає зміні параметру від найгіршого до найкращого значення. Точка з координатами {1, 1, 1,.....1} завжди відповідає гіпотетичному ідеальному об`єкту, який має найкращі із можливих значення по всім параметрам. Геометрична відстань від цієї вершини гіперкуба до точки, яка відповідає положенню конкретного об`єкту відповідає віддаленості його від ідеального значення і може слугувати оберненою величиною до комплексного “рейтинга” об`єкта. величину обернену рейтингу обєкта. Таким чином, ми маємо строгу, формалізовану процедуру отримання комплексного критерію, що має ясну геометричну інтерпретацію. У випадку нерівнозначимості різних параметрів при обчисленні відстаней достатньо добавити множники вагових коефіцієнтів, що відповідають значущості параметрів. Нормування відбувається в залежності від цілі оптимізації по конкретному критерію. Для нормування вихідної змінної Yk (у випадку, якщо ціллю оптимізації по даній змінній є знаходження мінімуму) використовується наступна формула Якщо метою оптимізацією по Yk є знаходження максимуму, то нормування відбувається по наступній формулі Де Yk, max – максимальне можливе значення для k-го критерію, Yk, min – мінімальне можливе значення для k-го критерію, Yki – поточне значення k-го критерію, Y’ki – нормоване поточне значення. Формула (1.3) варіюється в залежності від мети оптимізації по критерію Yk. У тому випадку, коли метою оптимізації є попадання параметру Yk в заданий інтервал, причому чим ближче до середини інтервалу – тим краще, то формула нормування простору приймає наступний вигляд Тут (YA, YB) – інтервал, до якого має попасти значення критерію, який підлягає оптимізації. Відстань між ідеальною та поточною точкою визначається як евклідова з доданням вагового коефіцієнту, що дозволяє урахувати нерівно значимість досягнення оптимуму окремих критеріїв для загальної мети. Вона (відстань) обчислюється за формулою Тут Li – відстань від ідеальної точки для i-го об’єкту, M – кількість критеріїв якості, j – номер поточного критерію якості, Y’ji – нормоване значення j-го критерію якості для i-го об’єкту, gj – ваговий коефіцієнт, що визначає значимість j-го критерію якості, при цьому виконується умова Для визначення рейтингу окремих об’єктів зручно користуватися величиною, що доповнює відстань до 1, а саме: Gi =1 – Li (4.7) Значення Gi тим більше, чим ближче об’єкт до ідеальної точки. Це дозволяє отримати зручний для порівняння рейтинг об’єктів: чим краще об’єкт – тим більше значення рейтингу він має. 5.2.3. Проблема визначення вагових коефіцієнтівЗадача визначення вагових коефіцієнтів при великій кількості параметрів якості є дуже складної. З одного боку неточне завдання ваги зовсім змінює розраховані рейтинги, з другого боку при великій кількості параметрів – це задача по складності порівняння з самою побудовою рейтингу. Як правило, при кількості параметрів більшій 3-4 навіть висококваліфікований спеціаліст має труднощі з цією задачею (правило 7±2). Тому в таких випадках використовується процедура формалізованого визначення вагових коефіцієнтів, яка базується на попарному порівнянні значимості параметрів. Задача попарного порівняння для будь-кого незрівнянно простіша ніж визначення всіх коефіцієнтів і, завдяки великій кількості градацій (таблиця 4.1). По результатам всіх відповідей виконується розрахунок вагових коефіцієнтів. Таблиця 4.1 Градації порівняння критеріїв по їх значущості
Для перетворення простору необхідно для кожного критерію задати мету, виконання якої забезпечить найкраще значення даного критерію. Можливі варіанти завдання мети, які використовуються в програмному засобі ПРІАМ приведені в таблиці 4.2. Як видно, частина з них фактично є обмеженнями, чи вказівками щодо виключення критерію з розгляду (ігнорувати). Розподілу на ціль оптимізації і обмеження в програмному засобі ПРІАМ при роботі немає для забезпечення зручності користувачу. Таблиця 4.2 Можливі цілі по кожному критерію
Ідея попарного порівняння Оскільки в реальних задачах значимість окремих показників для оцінки якості об`єкту різна, то необхідно підготувати таблицю попарного порівняння, буде використана для розрахунку вагових коефіцієнтів (дивись таблицю 4.4). В кожній графі таблиці повинно бути записано значення порівняння двох критеріїв (наприклад, еквівалентно, важливіше тощо, як в таблиці 4.1). Головна діагональ не заповнюється (при розрахунках вважається, що там нуль). Звертаємо вашу увагу, що ця таблиця не симетрична і порівняння потрібно проводити в напрямку, вказаному стрілкою. Це означає, що в графі, де розміщена стрілка порівнюється “Критерій 2” з “Критерієм 3”, але не навпаки. Для трьох рівнів порівняння заповнення таблиці виконується наступним чином. В тому випадку, коли критерії еквівалентні – в обидві симетричні комірки заноситься по 0,5; якщо, наприклад, “Критерій 2” важливіше “Критерію 3”, то в комірку в рядку “Критерій 2” заноситься 1, в то в комірку в рядку “Критерій 3” – 0. Після заповнення всієї таблиці знаходиться сума по рядкам і загальна суми. Суми по рядкам є ненормованими ваговими коефіцієнтами. Після ділення їх всіх на загальну суму отримуємо нормовані вагові коефіцієнти, сума яких дорівнює 1. Таблиця 4.4
5.3. Інші методи оптимізації5.3.1. Динамічне програмуванняДинамічне програмування – це математичний метод знаходження оптимальних розв’язків багатокрокових задач. Можливі задачі 1. Задача інвестування обмеженої суми в декілька об’єктів. 2. Календарне планування ресурсів. 3. Динамічне керування запасами. 4. Завантаження транспорту. Зауваження. 1. Оптимальний розв’язок на якому-небудь кроці не є оптимальним в цілому. 2. Хоча природа задачі є комбінаторною, для реальних ситуацій перебір всіх варіантів практично неможливий. Принцип оптимальності Беллмана в формулюванні Вентцель. Яким би не був стан системи перед наступним кроком, необхідно вибирати управління на цьому кроці так, щоб виграш на даному кроці плюс виграш на наступних кроках був максимальним. Математична постановка. Найти Варіанти. 1. Цільова функція мультиплікативна. Тобто 2. Число кроків нескінченне (n=µ). Це означає оптимальність безвідносно до точки, в якій операція закінчується. Наприклад, при виробничому плануванні. При цьому необхідно, щоб функції виграшу Fi і зміни стану не залежали від номеру кроку. Для розвязку використовується апарат харківських ланцюгів. Приклад описаний в [1]. Суть підходу до розв’язання задачі. 1. Оптимізація виконується методом послідовного наближення в два етапи: спочатку від останнього кроку до першого, а потім навпаки – від першого до останнього. 2. На першому етапі при русі від наступних кроків до попередніх знаходимо умовні оптимальні керування. Тобто, на кожному кроці керування забезпечує оптимальне продовження операції. 3. Так продовжується до першого кроку. Оскільки він не має попереднього, то його розв’язок не умовний оптимальний, а оптимальне керування, яке шукається. 4. Потім на другому етапі ми починаємо з першого. Тепер замість умовних ми знаходими оптимальні керування. Алгоритм. 1. Вибрати параметри (фазові координати), які характеризують стан S керованої системи перед кожним кроком. 2. Розчленувати операцію на кроки.. 3. Визначити множину крокових управлінь xi для кожного кроку і обмеження, які на них накладаються. 4. Визначити, який виграш проносить на i-му кроці керування xi, якщо перед цим система була в стані S, тобто записати функцію виграшу wi = fi(S,xi). 5. Визначити як зміниться стан S системи під впливом керування xi на i-му кроці, якщо вона переходить в новий стан S`=ji(S,xi). 6. Записати основне рекурентне рівняння динамічного програмування, яке обчислює умовний оптимальний виграш Wi(S) (починаючи з i–го кроку до кінця) через відому функцію Wi+1(S): 7. Виконати умовну оптимізацію останнього (m-го) кроку управління задаючи множину станів S, з яких можна за один крок дійти до кінцевого. Для кожного обчислюється умовний оптимальний виграш 8. Виконують умовну оптимізацію (m–1), (m–2) і далі кроків. На першому кроці знаходиться оптимальний виграш W*=W1(S0). 9. Виконується безумовна оптимізація. Беруть оптимальний розв’язок на 1-му кроці. Змінюється стан системи. Для знайденого стану знаходиться оптимальне управління на 2-му кроці і т.д.
Рис. 12.1.
Рис. 13.2.
Рис. 13.5.
Рис. 13.6 - Приклад описаний в [2]. 5.3.2. Нелінійне програмуванняМатематичний апарат для пошуку екстремуму нелінійних функцій при наявності обмежень Оскільки допустима множина розв’язків в загальному випадку не є випуклим, і навіть у випадку випуклості множина крайніх точок не є кінечною, загального методу не існує. Існують методи розв’язку окремих класі задач. Приклад. Кузнецов с.188. Метод множників Лагранжа. Використовується при знаходженні мінімуму чи максимуму для обмежень типу рівнянь та для диференційованих функцій f и gi. Умовний екстремум функції f знаходять з використанням функції Лагранжа Безусловний екстремум даної функції співпадає з умовним функції f. Це відпувається завдяки тому, що в точці екстремуму всі gi(x1,x2,…xm)=0 і, як наслідок, L=f. Таким чином для розв’язку задачі достатньо знайти безумовний екстремум функції Лагранжа. Для цього знаходять часткові похідні по невідомим і прирівнюють їх до нуля. Потім розв’язують отриману систему рівнянь. Приклад. Зайченко 3.1. с.88. 5.3.3. Стохастичне програмуванняЧасто параметри залежать від випадкових величин. Наприклад, вміст цукру в буряку, урожайність тощо. Оптимальність при наявності невизначеності Y=F(X,Z) Z – випадковий вектор з невідомим законом розподілу і його параметрами, або детермінований вектор з невідомими значеннями. Для розв’язання використовується принцип гарантованого результату. Виконується розв’язок модифікованої задачі 1. Одноетапна або жорстка постановка. План виконується з урахуванням всіх можливих станів природи. Корегування плану не допускається. (Задача 5.1. Зайченко с. 204.) 2. Двохетапна задача. Можливі зміни в плані після того, як стало відомо стан природи. (Задача Канторович с. 120.) Література до розділу 4. 1. Зайченко Ю. П., Шумилова С. А. Исследование операций: Сборник задач. – 2-е. изд., перераб. и доп. / Ю. П. Зайченко, С. А. Шумилова. – К.: Вища школа, 1990. – 239 с. 2. Вентцель Е. С. Исследование операций: задачи, принципы, методология. / Е. С. Вентцель. – М.: Наука, ГРФМЛ, 1980. – 208 с. 3. Кузнецов А. В., Холод Н. И., Костелевич Л. С. Руководство к решению задач по математическому программированию. / А. В. Кузнецов, Н. И. Холод, Л. С. Костелвич. – Мн.: Вышэйш. Школа, 1978. – 256 с. 4. Канторович Л. В., Горстко А. Б. Оптимальные решения в экономике / Л. В. Канторович, А. Б. Горстко. – М.: Наука, 1972. – 231 с. 5. Зуховицкий С. И., Авдеева Л. И. Линейное и выпуклое программирование / С. И. Зуховицкий, Л. И.Авдеева. - М.: Наука, ГРФМЛ, 1967. – 460 с. 6. Лапач............. 5.3.4. Стійке керуванняПринцип зовнішнього доповнення Стаффорда Бира “Керувати в даний момент часу необхідно так, щоб залишалася свобода вибору рішень в наступний момент часу, коли буде прийматися наступне рішення ” Д. Габор.
Рис. 15 - Схема гнучкого керування з числом степенів свободи 3 Практичні заняття1. Демонстрація необхідності планування експерименту1.1. Підвищення точності оцінокП.П. 1.1.1. і 1.1.2 взяті з В.В. Налимов, Т.И. Голикова “Логические основания планирования эксперимента”. Розглянемо різні схеми зважування і їх вплив на точність оцінка. 1.1.1. Традиційна схема зважування трьох об’єктів приведена в табл.. 1.Традиційна схема (таблиця 1) зважування передбачує зважування об’єктів по одному і попереднє “зважування” “ніщо” для визначення систематичної помилки пристрою для зважування. Таблиця 1. Традиційна схема зважування трьох об’єктів
Для визначення ваги виконуються наступні дії. Вага 1–го об’єкту А=(Y1 – Y0) Вага 2–го об’єкту B=(Y2 – Y0) Вага 3–го об’єкту C=(Y3 – Y0) Для визначення точності визначаємо дисперсію результатів зважування 1.1.2. Ефективна схема зважування з плануванням експериментуВиберемо іншу схему з використанням планування експерименту (табл.. 2). Таблиця 2. Ефективна схема зважування
Для визначення ваги об’єктів виконуються наступні дії Вага 1–го об’єкту А=(Y1 – Y2 – Y3 + Y4)/2 Вага 2–го об’єкту B=(–Y1 + Y2 – Y3 + Y4)/2 Вага 3–го об’єкту C=(–Y1 – Y2 + Y3 + Y4)/2 Дисперсія зважування Вона вдвічі менша, ніж при традиційній схемі. 1.1.3. Схема повного факторного експериментуПопробуємо використати схему повного факторного експерименту. Таблиця 3. Схема повного факторного експерименту
Дисперсія зважування Як ми бачимо дисперсія зменшилася ще вдвічі, але при цьому ми затратили вдвічі більше експериментів. 1.1.4. Схема з дублюванням експериментівВиконаємо зважування з дублюванням експериментів, використовуючи схему таблиці 2. Таблиця 4. Схема з дублюванням експериментів
Дисперсія зважування Дисперсія зважування тут як при ПФЕ, але ця схема дозволяє додатково визначити: - дисперсію відтворюваності (тобто рівень випадкової помилки); - наявність грубих викидів; - наявність залежності помилки зважувального пристрою від ваги об’єкту. 1.2. Забезпечення стійкості оцінокРозглядається вплив мультиколлінеарності та випадкової помилки на стійкість оцінок коефіцієнтів регресії. В таблиці 5 приведені системи рівнянь і їх корені. Системи 4: всі комбінації ортогональності/сильної закорельованості з наявністю/відсутністю помилки. Рівень помилки приблизно 6:%. Системи рівнянь взяті в зв’язку з тим, що коефіцієнти регресії знаходяться в результаті розв’язку системи нормальних рівнянь XTXB = XTY. Таблиця 5
Як видно з таблиці з таблиці 5 при розв’язку ортогональної системи рівнянь відносна помилка в отриманих коренях рівняння відповідає її рівню в вхідних даних. В не ортогональній системі помилка різко збільшується, деформуючи значення так, що навіть міняється знак. В обчислювальному плані це зв’язано з тим, що для ортогональної системи число обумовленості дорівнює 1, а для сильно закорельованої може досягати сотень і тисяч. Це приводить до зростання помилки в результатах при наявності помилки у вхідних даних. На рисунках 1 і 2 приведена геометрична інтерпретації вказаних ситуацій. Випадок 1 відповідає ортогональній ситуації, а рис. 2 сильно закорельованій. Рис. 17 - Геометрична інтерпретація З рисунків видно, що наявність помилки приводить до паралельного переносу “справжньої” прямої на невелику відстань, яка відповідає розміру внесеної помилки. В результаті відбувається і переміщення точки перетину прямих, яка є коренями системи рівнянь. Для ортогональної системи, в зв’язку з тим, що кут перетину дорівнює 90° точка перетину зміщується пропорційно переміщенню прямої. Для сильно закорельованої точка перетину зміщується дуже сильно. Зміщення тим більше чим гостріше кут перетину прямих (чим більше закорельованість).
Рис. 18 - Геометрична інтерпретація (сильно закорельована ситуація) 1.3. Забезпечення правильності визначення структуриРозглянемо вплив закорельованості і рівня випадкової помилки на можливість правильного визначення структури рівняння регресії. Ми маємо формулу Y = 2 + 5X1 + 0,2X2 – 0,1X3. По таблиці 6 і даній формулі розраховані значення відгуку без помилки і з помилкою. Таблиця 6
В таблиці 7 приведена таблиця коефіцієнтів кореляції для матриці, по якій буде розраховуватися модель. Таблиця 7. Таблиця коефіцієнтів кореляції
Після цього за допомогою програми регресійного аналізу з Excel розраховуємо коефіцієнти регресії. Відкидаємо не значимі, використовуючи критерій Ст`юдента. Виконуються 5 варіантів: 1. З точним значенням відгуку 2. З випадковою помилкою в інтервалі (0;1) 3. З випадковою помилкою в 5% відгуку 4. З випадковою помилкою в 10% відгуку 5. Самий гірший варіант (№2) рахується на ПРІАМ (чи вручну потрібним алгоритмом). Варіант 1. Для випадку точних відгуків коефіцієнти регресії точно співпадають зі значенням в формулі, по якій розраховувалися відгуки. Четвертий коефіцієнт практично дорівнює 0 і статистично не значимий. Таблиця 8. Коефіцієнти регресії для точних відгуків
Варіант 2. Для великого рівня шуму маємо ситуацію, відображену в таблиці 9. Добре видно, що значимим при такому рівні є тільки вільний член. Якщо ж робити так, як рекомендується в деяких підручниках), тобто вважати значимим (при закорельованості) ті коефіцієнти, для яких розрахункове значення більше 1, то в моделі з’явиться член при Х4 і зникнуть при Х1 і при Х2. Таблиця 9. Коефіцієнти регресії для відгуків з похибкою в інтервалі (0,1).
Опис одного і того є фізичного явища різними по загальній структурі (специфікації) математичними моделями. Для аналізу використовуються дві моделі зміни температури полум’я в залежності від часу: СРСР
Використання різних моделей одного і того ж процесу з метою отримання спектру прогнозів. Для апроксимації і наступного прогнозу використовуються наступні функції: - Лінійна - Показникові - Степенева Склад звіту 1. Завдання. 2. Формули отриманих апроксимаційних моделей. 3. Таблиці апроксимації і прогнозу. 4. Графіки апроксимації і прогнозу. 5. Порівняння якості апроксимації різних моделей. 6. Висновки. Приклад. Таблиця 2.1 Варіант тенденції до зростання.
Таблиця 2.2. Фактичні значення для прогнозу
Рис. 2.1 - Апроксимація і прогноз при тенденції до підйому Таблиця 2.3 Варіант тенденції до спаду
Таблиця 2.3 Варіант тенденції до спаду.
Рис. 2.2 - Апроксимація і прогноз при тенденції до спаду Стохастичний автомат (Марковські ланцюги) Автомат є математичною моделлю деякого пристрою чи системи дискретної дії. Така система деяку кількість вхідних та вихідних каналів і множину внутрішніх станів. Від вхідного сигналу змінюється стан системи та вихідний сигнал. Найбільш часто розглядаються скінчені автомати, в яких ці три множини скінчені. Автомат розглядається як п’ятірка {A,X,Y,d,l} (2.1) де А – скінчена множина внутрішніх станів, Х – скінчена множина вхідних сигналів, Y – скінчена множина вихідних сигналів; d: А´Х®А – однозначна функція переходів (із стану в стан), l: А´Х® Y– однозначна функція виходів. При невеликій кількості станів автомат часто описують за допомогою діаграми станів автомату (графу станів). Це напрямлений граф, вершини якого відповідають станам, а ребра сигналам, що з’єднують стани; назва ребра є назвою (кодом) сигналу; воно напрямлене від стану, в якому система знаходилася, до стану, в який система перейде під впливом даного сигналу. На рис. 2.1 зображено автомат, який виконує додавання в двійковій системі числення. Q0 – стан, в якому немає переносів. Q1 – стан, в якому виконано додавання одиниці, яка попередньо запам’яталася. Q2 – стан, в якому виконано два переносу одночасно. Q3 – стан, в якому запам’яталася одиниця для переносу в старший розрад. Q0 та Q1 є кінцевими станами, а Q2 та Q3 – проміжними. Якщо станів багато, то для опису автомату використовують таблиці. Елемент таблиці Аij містить рядок x:y, де х – код сигналу, що переводить систему зі стану I в стан j, а у – вихідний сигнал.
Рис. 2.1 - Приклад. Суматор двійкових чисел Досить широко зустрічаються такі різновиди автомату, у яких перехід із одного стану в інший виконується не детерміновано, а з певною ймовірністю. Такі автомати називаються стохастичними, тому що з зміною стану змінюється розподіл ймовірностей переходів. Стохастичний автомат — це такий процес або об’єкт, який має обмежену кількість станів, в яких він може знаходитись і задані ймовірності переходів з кожного стану в будь-який інший. Теоретичною базою стохастичного автомату є теорія марківських процесів. Не всі види марківських процесів є стохастичними автоматами. Марківськими називаються такі випадкові процеси в довільній системі для яких в будь який момент часу ймовірність переходу системи в інші стани не залежить від того, як система прийшла в даний стан, а залежить тільки від теперішнього стану системи. Розрізняють наступні види марківських процесів: 1. З дискретними станами та дискретним часом (ланцюг Маркова); 2. З неперервними станами та дискретним часом (марківські послідовності); 3. З дискретними станами та неперервним часом (неперервні ланцюги Маркова); 4. З неперервним часом та неперервними станами. Як стохастичний автомат розглядаються тільки процеси з дискретними станами. Стохастичним автоматом моделюється багато різноманітних процесів: процес загибелі та розмноження в біологічних системах, вибір покупцем товару в маркетингових дослідженнях тощо. В технічних задачах найбільш часто за допомогою стохастичного автомата моделюють технічний стан різних пристроїв. На рис. 2.2 показано приклад такої моделі, що описує літальний апарат (спрощено з [4]). Тут Г – стан готовності до польоту, КР – капітальний ремонт; С – списання; Р – ремонт; РР – регламентні роботи. Рис. 2.2 - Граф станів літального апарату Визначення станів Нехай Х є підмножина простору станів автомату S, а Х` – його доповнення до S. Ергодичні стани. Якщо кожного стану підмножини Х можна досягти з будь-якого іншого стану цієї підмножини, і ні з якого стану підмножини Х неможливо перейти ні в один зі станів Х`, то Х називається ергодичною множиною станів. Кожен зі станів цієї множини називається ергодичним станом. Якщо процес попав в ергодичну множину станів, то він не може його покинути. Нестійкі стани. Якщо будь-який стан множини Х досягається із будь-якого стану Х і при цьому можливий перехід хоча б із одного стану Х в стан із Х`, то така множина станів називається нестійкою. Кожен її стан в свою чергу називається нестійким. Поглинаючі стани. Якщо поглинаюча множина складається з одного стану, та такий стан називається поглинаючим. Якщо процес попадає в такий стан, то він залишається в ньому. Для поглинаючого стану ймовірність переходу в цей же стан pii=1, а pij=0 "i¹j. Будь-який марківський ланцюг повинен мати хоча б один ергодичний стан. Нестійких станів взагалі може не бути. Якщо перехід з одного стану в інший в ергодичній підмножині відбувається через регулярну кількість кроків, то це циклічна ергодична множина. Класифікація ланцюгів. 1. Поглинаючі ланцюги Маркова. Це такі ланцюги, в яких стійкі стани є поглинаючими. 2. Ергодичні ланцюги. Це такий ланцюг, який складається з одного ергодичної множини. Розділяються на циклічні, в яких процес приходить в кожен стан через певні інтервали і регулярні – неперіодичні ергодичні ланцюги. Наприклад, автомат описується наступною матрицею переходів: Тут є дві групи ергодичних станів: в першу входять стани s2 та s3, а в другу – s4. При цьому s4 є поглинаючим станом. Простий однорідний ланцюг Маркова визначається вектором ймовірностей станів у початковий момент і матрицею ймовірностей переходу. При цьому для кожного рядка матриці виконується умова Такий ланцюг має наступні властивості: Простий – закон розподілу (рядок матриці) залежить тільки від стану, в якому система знаходиться. Однорідний – якщо ймовірності переходу на певному інтервалі залежать тільки від довжини інтервалу, а не від точки відліку. P(ti)= P(t0)Pi(t) (2.6) Ергодичний - з кожного стану можна попасти в будь-який інший. Для ергодичного ланцюга існує граничний стан, в якому всі рядки матриці однакові. Для визначення граничного стану розв’язується система рівнянь наступного виду (система рівнянь Колмогорова): При вивчення поведінки ланцюгів звичайно з`ясовуються наступні питання. 1. Ймовірність переходу зі стану i в стан j через n кроків. 2. Очікувана кількість попадань процесу в конкретний нестійкий стан. 3. Середнє значення (і дисперсія) числа кроків, які необхідно зробити процесу для переходу із одного конкретного стану в інший. 4. Ймовірність попасти із конкретного нестійкого стану в задану ергодичну підмножину станів. 5. Середнє число кроків (і дисперсія), котрі пройде процес перед тим, як попасти в ергодичну підмножину станів. Поглинаючі ланцюги Канонічна форма матриці переходів Для поглинаючих ланцюгів це така форма матриці, в якій рядки і колонки матриці переставлені таким чином, що поглинаючі стани займають перші рядки та колонки. Ця матриця має наступну структурну форму: Вона складається як би з чотирьох матриць, де I – одинична, а 0 – нульова матриці. Фундаментальна матриця ланцюга Фундаментальна матриця ланцюга визначається наступним чином N=(I-Q)-1(2.9) Елементи матриці показують середню кількість попадань в відповідні стани (номер колонки), якщо рух починати зі стану, що відповідає номеру рядка Інша необхідна інформація обчислюється з наступних формул 1. Дисперсія числа попадань процесу в деякий заданий стан при певному початковому стані: N2=N(2Ndiag–I)–N[8]sqr. (2.10). Елементи матриці показують дисперсію кількості попадань в відповідні стани (номер колонки), якщо рух починати зі стану, що відповідає номеру рядка. 2. Середнє значення та дисперсія числа попадань процесу в заданий нестійкий стан. 2=(2N–I)-2; (2.11)де =Nx, аx – одиничний вектор. 3. Ймовірність того, що процес попаде в заданий поглинаючий стан (номер колонки), якщо він почне рух з заданого нестійкого стану (номер рядка) B=NR. (2.12) Приклад Процес описується наступною матрицею переходів: Після перестановок рядків та колонок отримаємо наступну канонічну форму матриці переходів: Зверніть увагу, що рядки тепер мають нові назви! Звідси Тоді канонічна матриця ланцюга матиме наступний вигляд Після цього Таким чином, якщо почати рух зі стану s1, то середнє число попадань в стан s4 (до того, як система попаде в один з поглинаючих станів) буде 3/2, а в s1– 2. Дисперсія цих значень дорівнює відповідно 9/4 і 20/4. Далі визначаємо Тобто, середнє значення числа попадань процесу в стан s1 до поглинання 3,5 при дисперсії цього значення 33/4. Тобто, якщо процес почнеться зі стану s1, то він з однаковою ймовірністю закінчиться в s3, або s2, Якщо ж він почнеться з s4, то ймовірність завершитися в s3 дорівнює 2/3. 2. Регресійний аналіз1.2.2. Формалізація задачіМатематика, подобно жернову перемалывает лишь то, что под нее засыпают. Как, засыпав лебеду, вы не получите пшеничной муки, так, исписав целые страницы формулами, вы не получите истины из ложных предпосылок. Томас Гекслі Все великолепие Вселенной четко выражается для них (животных — авт.) в виде а) того, с чем спариваются; б) того, что едят; в) того, от чего убегают, и г) камней. Это освобождает животных от ненужных мыслей и придает их сознанию остроту, направленную только на то, что действительно необходимо. Террі Пратчет «Творцы заклинаний» Ошибка, допущенная в первоначальной расстановке сил, едва ли может быть исправлена в ходе всей войны. Мольтке – А ну-ка быстро: как правильно– у рыбов нет зубов, у рыбей нет зубей или у рыб нет зуб? – У рыб нет зуб. – У рыб нет зубов! Но это тоже неправильно, потому что зубы у рыб есть. Понял? – Нет. – Ты выбираешь, какое из неправильных решений самое правильное, А они все неправильные. Елеонора Раткевич «Деревянный меч» Формалізація задачі є першим і обов’язковим етапом розв’язання будь-якої задачі. Від тго, наскільки правильно виконана формалізація залежить як вибір засобів і методів, так і ефективність результату. Помилки, які допущені на цьому етапі дуже важко, або й не можливо виправити на подальших (при обробці результатів експерименту). При формалізації виконується трансформація мети дослідження до виду, який придатний для використання математичних методів. Потрібно пам’ятати, що на цьому етапі відбувається більше всього помилок. Особливо треба остерігатися “вихолощення” чи підміни мети розв’язуваної задачі. Це приводить до того, що розв’язується не та задача, або отриманий розв’язок немає ніякого практичного сенсу. Тому після проведення формалізації необхідно провести її верифікацію. Необхідно відповісти на питання: чи дозволяють результати, які будуть отримані досягнути поставленої мети дослідження. Формалізація складається з наступних етапів. 1. Формулювання чітких цілей в термінології предметної області. 2. Визначення формалізованої прикладної мети дослідження. 3. Аналіз і структурування об’єкту дослідження. 4. Вибір методів і засобів розв’язку. 5. Визначення необхідних ресурсів для проведення досліджень. Між переліченими етапами немає чітких меж, так як вони взаємопов’язані. Наприклад, наявні ресурси визначають обсяг інформації, яку можна отримати. Таким чином, ресурси опосередковано впливають на можливість досягнення мети. 1.2.2.1. Визначення формалізованої прикладної мети дослідженняПрежде всего необходимо установить в чем именно заключается «задача». Это замечание связано с тем, что реальные ситуации редко бывают четко очерченными, а сложное взаимодействие с окружающей средой часто делает точное описание затруднительным. Р.Р. Мак-Лоун «Математическое моделирование – искусство применения математики» в Від формалізованої прикладної мети дослідження залежить вибір методів розвязку і вона ж визначає потребу в ресурсах. Можливі наступні формалізовані цілі дослідження: 1. Виявлення наявності зв’язків між незалежними і залежними змінними. 2. Апроксимація деякої множини даних моделлю. 3. Пошук оптимальних умов. 4. Визначення структури зв’язків між незалежними і залежними змінними і отримання моделі, що відображає цю структуру. Під апроксимацією розуміють заміну однієї функції (найчастіше заданої таблично) на іншу з наперед заданою точністю. В таких задачах статистичні характеристики моделі практично не грають ніякої ролі. Але, якщо ви вибрали цей шлях, необхідно пам’ятати про небезпеки, які чекають дослідника на ньому. Добиваючись високої точності в вузлах апроксимації (точках експерименту або клітинках таблиці) без урахування особливостей задачі і статистичних характеристик, можна опинитись в ситуації, коли в проміжках між вузлами значення, розраховані по моделі, будуть дуже (навіть в десятки і сотні разів) відрізнятися від фактичних. Причиною є переускладнення моделі ефектами високих порядків і появи осциляції. При цьому апроксимізаційна функція між вузлами має дуже складну форму і інтерполяція по такій моделі не має практичного сенсу. Особливо це характерно при апроксимації функцій, які швидко міняються. Апроксимація звичайно використовується при наявності вже вивченого процесу, поведінка якого детально описана таблицями, графіками, номограмами, а нам необхідно використати ці дані в автоматизованих системах, де зручніше обчислювати за формулами. При виборі точок з таблиць, графіків, номограм слід користуватися загальними правилами планування експерименту, що полегшується відсутністю обмежень на кількість дослідів (для графічних джерел інформації) і наявності повної інформації про форму залежності. При пошуку оптимальних умов в багатьох випадках не потребує побудови моделі і вимагає менших ресурсів. В даній роботі під побудовою моделі мається на увазі побудова лінійної за параметрами регресійної моделі. Експеримент при цьому може бути натурним, напівнатурним, обчислювальним чи результатом експертного опитування. Модель має бути такою, щоб її дійсно можна було використовувати для дослідження об’єкту: відповідати об’єкту не тільки по точності прогнозу результату, – її структура повинна відображати структуру зв’язків між незалежними змінними та відгуком. Звертаємо вашу увагу на два моменти, які по різному сприймаються статистиками та спеціалістами в предметній галузі: адекватність моделі і її структура. Користувач звичайно оцінює адекватність моделі (тобто відповідність моделі об’єкту) по середньому та максимальному абсолютному та відносному відхиленню прогнозованих значень від експериментальних. В статистиці для перевірки адекватності звичайно використовується критерій Фішера. Модель може бути адекватною по критерію Фішера і неадекватною з точки зору користувача і навпаки. Користувач має на увазі, що спеціальна структура моделі завжди відповідає структурі зв’язків об’єкту і на основі її аналізу робить висновки про сам об’єкт. Більшість статистиків вважає, що структура моделі не має ніякого відношення до дійсної структурі, а користувач повинен задовольнитися будь-якою моделлю з хорошими статистичними показниками. Звичайно, дослідника навряд чи це влаштує. Насправді, такі моделі дуже важко будувати, тому більшість статистиків неохоче береться за такі задачі. Вище перелічені цілі в чистому виді. Насправді часто необхідно одночасно досягти кількох цілей одночасно. Наприклад, отримати модель і виконати пошук оптимальних умов. В цій ситуації необхідно вибрати один з варіантів. Перший: спочатку найти оптимальні умови функціонування об’єкту, а потім побудувати модель, яка описує його поведінку в оптимальній області. Другий: спочатку побудувати модель, а потім за допомогою обчислювального експерименту знайти оптимум. Вибір варіанту залежить від наявних ресурсів і конкретних умов задачі. 1.2.3. Аналіз и структурування об’єкту дослідженняНикогда не строй планов, не выведав о противнике все, что можно. Не бойся менять планы, если получил новые сведения. Никогда не думай, что тебе известно все. И никогда не жди, пока узнаешь все. Роберт Джордан, «Властелин Хаоса» При аналізі і структуруванні об’єкту дослідження вибираються залежні змінні, складається список незалежних змінних, визначається склад контрольованих некерованих змінних і керованих незалежних змінних, значення яких буде зафіксовано; рівні варіювання для незалежних змінних. Залежні змінні (відгуки) повинні відповідати наступним вимогам: 1. Мати фізичний сенс і досить повно характеризувати досліджуваний процес чи явище. 2. Бути відтворюваними, тобто при повторенні дослідів в номінально однакових умовах отримані значення повинні співпадати з точністю до випадкової похибки. 3. Кожному набору значень незалежних змінних повинно відповідати одне (з точністю до випадкової помилки) значення відгуку. 4. Мати вимірювані значення при будь якій можливій комбінації вибраних рівнів варіювання факторів. Незалежні змінні (фактори) повинні відповідати наступним вимогам: 1. Повинні бути керованими (можливість встановлювати і підтримувати необхідні значення в процесі експерименту). 2. Не повинні залежати від інших змінних (можливість керувати кожною змінною незалежно від інших). 3. Область сумісного існування незалежних змінних повинна мати форму гіперпаралелепіпеда. Тобто в межах заданих меж змін факторів можливі будь які їх комбінації. Ніякі комбінації не повинні приводити до небажаних наслідків (наприклад, аварії устаткування, якісну зміну процесу тощо). 4. Повинні бути детермінованими величинами. 5. Інтервал зміни кожної незалежної змінної не повинен бути занадто малим, так як в такому випадку змінна може не впливати на відгук. Небажано встановлювати інтервал рівним вимогам технічних умов чи допусків – варіювання змінної в такому інтервалі, як правило, не впливає на відгук. Разом з тим, якщо інтервал дуже великий, то процес може вести себе досить складно і для надійного його опису може не вистачити ресурсів. Рівні варіювання факторів повинні вибиратися з урахуванням: апріорної інформації про характер впливу кожної змінної на відгук; роздільної здатності контрольно-вимірювальної апаратури; методів реєстрації та встановлення факторів; виду залежності відгуку від конкретної змінної. Так при лінійній залежності достатньо двох рівнів, при параболічній – трьох тощо. Якщо апріорна інформація відсутня, то число рівнів потрібно брати з запасом (4–8). Значення рівнів варіювання бажано розміщувати рівномірно. При необхідності (з метою отримання інформації) можуть розміщуватися нерівномірно. Але при цьому бажано не допускати, щоб сусідні значення рівнів сильно відрізнялись (в 8 – 10 разів). В такому випадку бажано перейти до логарифмічної шкали по даному фактору (в робочій матриці xi замінити на logxi). 1. Незалежні змінні повинні бути однозначні: одному значенню змінної повинно відповідати одне (з точністю до випадкової похибки) значення відгуку. 2. Множина факторів повинна бути повна (з точки зору розв’язання даної конкретної задачі). Тобто вибраного набору факторів повинно бути достатньо для пояснення поведінки залежних змінних. 3. Точность фіксації факторів повинна бути високою. Це означає, що мінімальна різниця між значеннями сусідніх рівнів варіювання повинна суттєво перевищувати точність встановлення і підтримки даного параметру. По результатам аналізу і структуризації об’єкту дослідження створюють таблиці, які містять інформацію про незалежні керовані змінні, некерованих, але контрольованих, фіксованих і залежних змінних. Для керованих незалежних змінних в таблиці має бути наступна інформація: назва змінної, одиниці виміру; значення рівнів варіювання, точність підтримання рівнів, тип змінної. Повинні бути перелічені змінні та їх значення, які будуть зафіксовані в експерименті. Бажано також перелічити некеровані контрольовані змінні, які можуть впливати на відгук. При обмеженнях на можливі комбінації взаємних значень незалежних змінних необхідно описати область дозволених значень. Для всіх залежних змінних необхідно вказати назви, одиниці вимірів, а якщо виміри непрямі, то – методику їх вимірювання. При виборі рівнів варіювання необхідно слідкувати, щоб не була розривною область планування. Наприклад, один і той же препарат може мати якісно різний вплив на чоловіків і жінок (до протилежного); для багатьох сплавів певні значення складу приводять до різкої зміни властивостей (наприклад, бронза). В таких ситуаціях формально отримані моделі не відповідають дійсності. В подібних випадках необхідно будувати моделі окремо для кожної області. Звертаємо особливу увагу на недоцільність спроб перекласти роботу, яку повинна зробити людина на обчислювальну машину. Найбільш поширеною помилкою є ситуація, коли замість аналізу процесу і вибору найбільш впливових 10-20 факторів, беруть кілька десятків факторів з надією, що машиною буде виконано відбір. В зв’язку з цим корисно пам’ятати: - При використанні будь-яких алгоритмів і програмних засобів при рості кількості потенціальних регресорів результати відбору різко погіршуються (практично всі програми, крім ПРІАМ, при кількості регресорів більше 80-100 дають повністю неадекватні результати). - Оскільки для отримання адекватної моделі необхідно аналізувати ефекти високих степенів і взаємодії, то кількість регресорів, які необхідно аналізувати, для кількох десятків незалежних змінних буде досягати десятків і сотень мільйонів. - Чим більше незалежних змінних, тим більше ресурсів (експериментів) необхідно провести для гарантованого отримання якісної моделі. Фізична складність проведення експерименту при цьому зростає навіть швидше, ніж обчислювальна. - Наслідком ускладнення експерименту завжди є підвищення рівня “шуму”. В таких експериментах замість кількох факторів, які сильно впливають, є дуже багато слабких факторів. При цьому зменшується надійність правильного визначення структури. 2.2. Побудова математичних моделей за експериментальними данимиТак как плохо спланированный опыт мало информативен, что нельзя исправить самой лучшей статистической техникой, то планирование эксперимента становится особо важным составным элементом статистики. Л. Закс “Статистическое оценивание” Планування експерименту – розділ математичної статистики, який займається формуванням оптимальних матриць експерименту. В теорії планування експеримент, який проводиться за спеціальною матрицею експерименту, яка відповідає певним критеріям оптимальності, називається активним, а у всіх інших випадках – пасивним, незалежно від того чи дослідник планував експеримент, користуючись певними своїми міркуваннями. Єдиним виключенням є випадок повного факторного експерименту (ПФЕ), який є окремим видом багатофакторного регулярного плану, і утворюється у випадку повного перебору всіх варіантів комбінацій рівнів варіювання факторів. Необхідність планування або формування вибірки признається для всіх статистичних методів. Це основний спосіб домогтися виконання передумов та допущень, що висуваються при розробці методів, без чого використання їх некоректно. Для більшості методів в наш час існує тільки набір певних рекомендацій та перевірок, наприклад, подвійне сліпе дослідження тощо. Найбільш розвиненим є планування регресійних та дисперсійних експериментів, тому іноді воно подається як частина відповідно регресійного та дисперсійного аналізу. В нашому курсі вивчається регресійний аналіз, в зв’язку з цим ми розглядаємо планування регресійних експериментів. В регресійному аналізі планування експериментів, як правило, використовується для моделей, лінійних відносно параметрів. Мається на увазі, що модель має вигляд алгебраїчної суми якихось функцій (загальний вираз лінійний відносно невідомих параметрів bi). Найбільш часто такими функціями виступають поліноми та тригонометричні функції (синус, косинус), але, в загальному випадку, це можуть бути довільні (і різні в одному і тому ж виразі) функції. Є класи функцій, які можливо привести до лінійних, наприклад, логарифмуючи їх. Як правило, в наукових та інженерних дослідженнях використовуються моделі, лінійні відносно параметрів. Це зв`язано з наступними причинами: - матриці для нелінійної регресії, як правило, погано обумовлені, що порушує ряд передумов регресійного аналізу та робить його використання некоректним; - складність інтерпретації для багатофакторних моделей; - за Швирковим В. В. в репрезентативній виборці зв’язок між змінними лінійний (змінні можуть бути довільними функціями), а будь-яка нелінійність викликана впливом неврахованих причин, тому використання нелінійного регресійного аналізу теоретично необґрунтовано. Оптимальність плану розуміється з точки зору досягнення деякого критерію. Існує багато різновидів оптимальності і відповідно видів оптимальних планів. Найбільш широко використовуються D-оптимальні плани, що забезпечують мінімізацію розсіювання оцінок коефіцієнтів регресії. Класичні плани мали однакову кількість рівнів варіювання для всіх факторів і відповідно називалися планами 1-го, 2-го та іноді більш високих порядків (наприклад, 3к, 4к). Вершиною класичного планування експерименту стали багатофакторні регулярні плани, розроблені Бродським В.З. В цих планах кожен фактор може мати число рівнів варіювання, відмінне від інших. Таким чином ці плани дозволяють будувати D-оптимальний план під конкретну задачу. Основним недоліком класичних планів експерименту є те, що вони є оптимальними тільки для певної структури рівняння регресії, яку необхідно знати ще до проведення експерименту та побудови плану. Якщо фактична структура буде відрізнятися від тієї, яку визначив дослідник до побудови плану, то план не буде оптимальним. В зв`язку з цим були створені робастні плани експерименту. Особливістю цих планів є то, що вони залишаються оптимальними, чи близькими до оптимальних, незалежно від того, яка буде структура рівняння регресії. Для робастних планів характерним є те, що точки плану розміщені рівномірно в багатофакторному просторі, а також мінімальна закорельованість між собою будь яких ефектів (як головних, так і взаємодій). В робастних планах головним є забезпечення найкращих умов для визначення структури рівняння регресії. Наслідком виконання цієї умови є забезпечення стійкості коефіцієнтів (аналог D-оптимальності) та виконання ряду передумов регресійного аналізу). Зараз існує три види робастних планів: - плани на основі ЛПt-рівномірно розподілених послідовностей; - робастні плани експерименту на базі багатофакторних регулярних планів; - плани узагальненої свастики. Багатофакторні регулярні плани мають форму багатовимірної регулярної сітки, а плани “узагальненої свастики” та плани на базі ЛП??-чисел – більш складну форму, що видно з рисунків 1.1 та 1.2 відповідно. Рис. 1.1 - Діаграма розсіяння для плану узагальненої свастики – 2 фактори, 6 дослідів
Рис. 1.2 - Діаграма розсіяння для плану на основі ЛПt - чисел для 16 дослідів Кількість дослідів для плану для побудови моделі розраховується по наступній формулі (не враховуючи дублюючих експериментів): де m - число незалежних змінних (факторів), Fi - число рівнів варіювання для кожної незалежної змінної. Ця формула базується на допущенні Саттерзвайта про те, що розподіл відносної сили впливу ефектів, відповідальних за процес, відбувається по експоненті. При пошуку оптимальних умов число експериментів визначається формулою: Nрасч = ln(1 – P)/ (1 – F), (1.2) де: Р – ймовірність попадання в область оптимуму, F - доля простору, яка містить оптимум по відношенню до загальним його розмірам[9] Наприклад, при Р=0,99 і F=0,1 – N=44. Значення Р,F вибираються із апріорних відомостей про процес, об`єкт. Для N рекомендується брати значення, найближче до числа 2 в степені k (k - довільне ціле число) в зв`язку з особливостями алгоритму генерації плану ЛП?-чисел. Недоліком цієї формули з точки зору практичного використання є неможливість достовірної оцінки F. Емпірично встановлено, що значення F зменшується з ростом розмірності простору (числа незалежних змінних). Для практичної мети можна скористатися таблицею 1.1. Таблиця 1.1
Максимально необхідна кількість дослідів для проведення експериментальних досліджень визначається по формулі: Nmax = Nрозр x k1 + Nконтр x k2 + P x Nрозр, (1.3) де Nрозр - необхідне число дослідів, розраховане по формулі (1.1); Nконтр - число контрольних дослідів; k1, k2 - кратність дублювання експериментів в навчаючій )по якій будується модель) і контрольній матриці відповідно.; Р - очікувана доля бракованих експериментів, які потрібно буде переробити. Звичайно, k1=2:3, k2=1, Nконтр=0,25xNрозр, Р=0,1. Звісно, ви можете прийняти Nmax=Nрозр, але при цьому необхідно зважити на можливі негативні наслідки такого кроку. Так, відсутність контрольної вибірки не дозволяє надійно перевірити прогностичні властивості моделі. Відсутність повторних дослідів (при k1=1) не дозволяє, по-перше, провести відбракування аномальних спостережень, а по-друге, визначити дисперсію відтворення. При цьому збільшується ймовірність неправильного визначення структури рівняння моделі. В цій ситуації ми можемо або “недобрати” членів в модель, якщо задана апріорно дисперсія занадто велика, або "перебрати" в протилежному випадку. У випадку "недобору" ми не включимо в модель ефекти, які статистично значимо впливають на відгук, а при "переборі" в модель попадуть "шумові" ефекти. І одне, і інше рівним чином небажано. При виконанні робіт досягається компроміс між метою та виділеними ресурсами. Результатом роботи буде вибір кількості рівнів варіювання незалежних змінних и формування завдання на генерацію плану в вигляді виразу виду 2kx3ix4j//N, (1.4) де k, i, j - кількість змінних, які варіюються відповідно з кількістю рівнів 2, 3... і т.д., N – число дослідів. Серед великої кількості програмних засобів лише незначна частина має функції генерації планів. Як правило, це примітивні класичні плани. Лише два програмні засоби можуть генерувати робастні плани експерименту. Це програмні засоби DESFACT та ПРІАМ. DESFACT дозволяє генерувати багатофакторні регулярні плани, але спеціальне завдання може забезпечити побудову за допомогою нього робастних планів. ПРІАМ генерує робастні плани на базі ЛПtрівномірно розподілених послідовностей або чисел Холтона, крім того, він може трансформувати ці плани при наявності факторів типу: склад сплаву чи розчину, де сума значень дорівнює в кожному рядку 100%. 3. Регресійний аналіз3.1. Попередній аналіз результатів експериментуАналіз однорідності дисперсій Після виконання експериментів необхідно провести попередню обробку результатів. На цьому етапі розраховуються середні значення відгуку та дисперсії в кожному досліді. Після цього, використовуючи критерій Кохрена, перевіряють однорідність дисперсій та розраховують дисперсію відтворюваності. Розрахунок критерію Кохрена виконується по формулі де S2max — максимальна із дисперсій; Si2 — дисперсії, розраховані в кожному досліді по повторним (дублюючим) дослідам по формулі де n — кількість повторювань дослідів в номінально однакових умовах; Результат порівнюється з табличним, і якщо Gрасч < Gтабл, ?, n-1,N, то гіпотеза про однорідність приймається і дисперсія відтворюваності розраховується по формулі Особливо цікавою є ситуація, коли перевірка по G-критерію показує, що дисперсії дослідів неоднорідні. Що потрібно робити в такій ситуації? Причиною неоднорідності дисперсій можуть бути або грубі помилки в результатах експерименту, так звані “викиди”, або закон розподілу помилки, який відрізняється від нормального. Для того, щоб визначити, яка причина викликала в конкретному випадку неоднорідність дисперсій, необхідно проаналізувати значення відгуку в тому експерименті, в котрому дисперсія найбільша. Спеціаліст має прийняти рішення, чи є це викидом. Якщо це викид, то цей експеримент необхідно провести ще раз для отримання нормальногу результату. Якщо це не викид, то закон розподілу помилки не є нормальним, або він є нормальним з так званими “важкими хвостами”. Дуже часто така ситуація спостерігається при проведенні випробувань на міцність до зруйнування. В цій ситуації ви можете продовжувати обробку як звичайно, але при цьому необхідно пам`ятати, що користуватися інтервальними оцінками (для коефіцієнтів, відгуків тощо) некоректно[10]. Теоретично вважається необхідним корегування коефіцієнтів моделі, наприклад, використовуючи метод найменших модулів, але на практиці така необхідність виникає дуже рідко. Якщо отримана модель, що задовольняє поставленим задачам (наприклад, по описуючим та прогностичним властивостям), то необхідності в корегуванні немає. Визначення рівня впливу “шуму” Перед тим як почати роботу по побудові моделі, бажано визначити, чи можливо взагалі з цих даних виділити якусь закономірність. Це можливо формально визначити перевіряючи, чи належать до однієї генеральної сукупності дисперсія відносно загального середнього і дисперсія відтворюваності. де Позитивна відповідь на це запитання означає, що з ладанним рівнем значимості в наших даних немає ніякої закономірності. Причини такої ситуації можуть бути наступні: — рівень впливу неконтрольованих факторів дуже високий і на фоні їх дії корисна інформація не проявляється; — неправильно вибрані незалежні змінні; — неправильно вибрані інтервал чи рівні варіювання незалежних змінних і вони внаслідок цього не впливають значимо на відгук, тобто в експеримент не включена частина значимо впливаючих факторів, або інтервал їх зміни занадто вузький ( чи занадто широкий при двох рівнях варіювання). В такій ситуації по об`єктивним причинам отримати якісну модель скоріш за все не вдасться. Тому необхідно старанно проаналізувати умови проведення експерименту та формалізацію, а потім провести нові дослідження в нових умовах, або прийняти отриманий результат для врахування факту відсутності статистично значимого зв’язку між незалежними змінними і відгуком для використання в наступних практичних дослідженнях. 3.2. Перетворення данихНикакое преобразование, в том числе и линейное, не может увеличить количеств полезной или мешающей информации, содержащейся в первичном материале, а может лишь разрушить часть полезной информации. Оптимальные (достаточные) преобразования сохраняют всю полезную информацию, максимально разрушая ненужную. …Любые преобразования, в том числе и оптимальные, неизбежно сопровождаются внесением добавочных шумов, что также понижает эффективность приема. Ф. М. Гольцман “Статистические модели интерпретации” Побудові моделі передує етап перетворення вихідної матриці незалежних змінних. Перетворення необхідні для: - формування моделі, достатньо складної для адекватного опису процесу або явища (ортогональні контрасти і взаємодії); - забезпечення стійкості структури і коефіцієнтів рівняння регресії (ортогональні контрасти та нормування); - перетворення області експерименту складної форми до стандартного виду (див. підрозділ 3.4 “Конструювання плану в нестандартних областях”; - врахування особливостей залежності факторів (наприклад, логарифмування та інші спеціальні перетворення). До стандартних перетворень відносять побудову ортогональних контрастів, нормування та побудову взаємодій. Ортогональні контрасти є поліномами Чебишева[11] першого, другого та вищих степенів від вихідного стовпчика змінної. Степінь не може бути вище, ніж число рівнів варіювання змінної мінус одиницю. Всі новостворені стовпці будуть ортогональні один до одного. Ортогональність може бути порушена, якщо рівні варіювання змінної розміщені на числовій осі дуже нерівномірно — розрізняються на порядок і більше. В такому випадку між змінною xi і відгуком існує логарифмічна залежність і необхідно виконати заміну x`i = ln xi. В подальшому при стандартних перетвореннях для цієї змінної необхідно будувати ортогональний контраст тільки першого порядку. Якщо ж не виконати перетворення до ортогональних контрастів, а будувати матрицю x, x2, x3 і т.д., то її стовпці будуть сильно закорельовані. Більш того, це так звана матриця Гільберта, яка з ростом степені швидко стає погано обумовленою, а потім і виродженою (з степені 8), незалежно від того як вибрано вихідний стовпчик. Переваги: 1. Вони найменше відхиляються від 0 на відрізку [–1;1] 2. Забезпечують більш швидку збіжність розкладання функцій порівняно з розкладанням в степеневий ряд чи в ряд по іншим спеціальним розкладенням чи функціям. 3. Вони дозволяють обчислювати значення функції заданої точності по меншій кількості членів ряду, або підвищити точність обчислень. 4. При виборі як вузлів інтерполяції коренів багаточленів Чебышева першого роду мінімізується залишок інтерполяційної формули. 5. Розрахунок по ряду квадратурних формул при використання поліномів Чебишева можливо вести накопиченням без перерахування коефіцієнтів. Поліноми Чебишева в загальному вигляді є поліноміальними функціями від рівнів варіювання вихідних факторів.: f1iu = xiu = a11i (Xiu + a10i); (3.6) f2iu = a22i (x2iu + a21i xiu i + a20i); (3.7) f3iu = a33i (x3iu + a32i x2iu i + a31i xiu i + a30i); (3.8) і т.д. Де i - номер фактору, u — номер досліду, Xiu — вихідні значення рівнів варіювання. Значення коефіцієнтів знаходяться з наступних умов де fрiu и fр'iu ортогональні контрасти степені p і p' для фактору Xi. Підставляючи вирази для ортогональних контрастів у відповідні формули ми отримуємо системи лінійних рівнянь, корені яких і будуть коефіцієнтами ортогональних поліномів Чебишева. Для поліномів першого та другого порядку ці корені розраховуються по наступним формулам: де a11i, a22i, a33i встановлюються таким чином, щоб розраховані значення поліномів Чебишева змінювалися в інтервалі (–1, 1). Але для забезпечення доброї обумовленісті однієї ортогональності недостатньо. Якщо значення змінних сильно відрізняються одне від одного, то це може приводити до помилок, в зв`язку з погіршенням обумовленості матриці та накопиченню похибки при обчислювальних процедурах. Нормування пропонується виконувати так щоб суми квадратів по стовпчикам були однакові Третьою стандартною операцією є побудова взаємодій. Не треба путати взаємодії зі взаємовпливом. Взаємовплив — це вплив одного фактора на інший, а взаємодія — сумісний вплив кількох факторів на відгук. Результатом взаємодії є така поведінка відгуку, яка не може бути пояснена простим складанням дії факторів. Взаємодії будують по членним перемноженням відповідних стовпців ефектів. ПРІАМ дозволяє автоматично будувати будь-які типи взаємодій. Звичайно достатньо подвійних взаємодій, оскільки вважається, що чим складніша взаємодія, тим менше ймовірність її впливу на відгук. Але можуть бути процеси, де складні взаємодії фізично присутні і їх необхідно будувати і аналізувати. Для повного факторного експерименту необхідно будувати всі можливі види взаємодій, тобто в матриці повинні бути взаємодії від подвійних до таких, що отримані перемноженням m стовпців ортогональних контрастів, де m — число вихідних факторів. Для матриці ПФЕ при невиконанні цієї умови можлива невдача при побудові інформативної і адекватної моделі. Крім вказаних вище загальних перетворень досить часто зустрічаються перетворення, які пов`язані з особливостями конкретної задачі. Такі перетворення необхідно виконати до описаних вище стандартних перетворень. Найбільш часто зустрічаються наступні перетворення. 1. Перетворення для приведення області експерименту до стандартного виду. 2. Логарифмування окремої змінної Xi. Таке перетворення виконується в тому випадку, коли інтервал варіювання змінної дуже великий (найбільше значення більш ніж у 10 разів більше найменшого). Такий інтервал, як правило, свідчить про логарифмічну залежність відгуку від Xi. В зв`язку з цим змінну потрібно прологарифмувати, а при подальших перетвореннях будувати від неї ТІЛЬКИ ортогональний поліном першого порядку. Наприклад, у фармакологічних дослідженнях таким фактором може бути час, якщо він змінюється від кількох годин до кількох діб. 3.3. Побудова коефіцієнтів математичної моделі і їх статистичних характеристикРозрахунок коефіцієнтів математичної моделі базується на використанні методу найменьших квадратів (МНК). Суть його в пошуку такої математичної моделі, для якої сума квадратів відхилень розрахованих по моделі значень відгуку від експериментальних буде мінімальна, тобто Q = S(Yi – Yiексп)2 ® min (3.15) Якщо задати вид моделі, то взявши часткові похідні від приведеного функціоналу по невідомим параметрам і прирівнявши їх до нуля, отримаємо систему лінійних рівнянь, коренями якої і є коефіцієнти моделі. Із сукупності рівнянь виду XTXB = XTY, (3.16) де B — вектор невідомих коефіцієнтів регресії; Y — вектор результатів експериментів (значень відгуку); Х — умови експерименту (значення незалежних змінних); T — знак транспонування матриці. Для знаходження коренів звичайно використовують метод Гауса з ведучим елементом. До недоліків МНК відноситься нестійкість його до викидів — при наявності їх модель занадто “перетягується” до цих спостережень і, таким чином, спотворюється. Взагалі-то кажучи, оцінки по методу МНК співпадають з оцінками по максимуму правдоподібності тільки у випадку нормального розподілу похибок. У всіх інших випадках необхідно корегування, або використання інших методів. Тому в тих випадках, коли передбачається можливість викидів, використовується метод найменших модулів (МНМ), в якому використовується функціонал Q = |Yi - Yiексп| ® min У випадку ортогональної матриці система розпадається на окремі рівняння, незалежні одне від одного і коефіцієнти регресії знаходяться по формулі: Індівідуальні довірчі інтервали для коефіцієнтів регресії визначається по формулі: де s — середнє квадратичне відхилення (корінь квадратний з дисперсії відтворюваності), cii - діагональний елемент матриці дисперсій-ковариацій, тобто матриці (XTX)-1, яка утворюється в процесі розв`язання системи рівнянь, tµ,n — табличне значення критерію Стюдента з рівнем значимості µ, і n степенями свободи. При цьому n = N(n-1) для випадку, коли в кожному експерименті n повторів и n = n-1, коли відтворюваності обчислюється по n окремим дослідам. Для більш точного визначення положення вектора істинних значень коефіцієнтів регресії використовують спільну довірчу область або інтервали Бонферроні. Довірчі інтервали можна розраховувати тільки в тому випадку, коли похибка розподілена по нормальному закону. В практичній діяльності аналіз довірчих інтервалів майже ніколи не виконують (крім однофакторної регресії!). Це зв`язано з тим, що коли модель має задовільні характеристики по опису досліджуваного процесу, то інші її характеристики вважають менш значимими. Слід пам`ятати, що величина коефіцієнта регресії може слугувати характеристикою його значущості відносно інших коефіцієнтів тільки у випадку ортонормованої матриці. При наявності мультиколлінеарності необхідно правильно визначити структуру рівняння регресії, оскільки в такому випадку величина коефіцієнта буде залежати від послідовності включення регресорів у модель. Знак коефіцієнту регресії однозначно вказує на напрямок впливу ефекту натуральної змінної тільки для лінійних ефектів. У всіх інших випадках необхідно аналізувати цю залежність, наприклад, за допомогою графіків часткових рівнянь регресії. Звичайно для перевірки значимості коефіцієнта регресії використовують значення t, долю участі, значення F для включення та деякі інші показники. При використанні критерію Стюдента розраховується: Якщо t > tµ,n то коефіцієнт значимий, інакше – ні. Строго кажучи, обґрунтоване використання цього критерію можливе у випадку повного факторного експерименту, коли всі стовпці матриці ортогональні. У всіх інших випадках t не дає правильного уявлення про значимість коефіцієнта. Доля участі — показник, який вираховується як доля від загальної суми квадратів, яку пояснює даний регресор. Іноді обчислюють b-коефіцієнт b = bi.(Sxi/Sy) Він показує наскільки змінюється значення відгуку при змінюванні значення даного регресора на величину його середньоквадратичної помилки. Потрібно мати на увазі, що вказані показники (коефіцієнт кореляції, доля участі, значення t, значення F для включення тощо) узгоджуються між собою тільки у випадку повної ортогональності матриці, по якій обчислюють коефіцієнти регресії. У всіх інших випадках вони можуть протирічити один одному. Така ситуація служить непрямою ознакою неправильного визначення структури рівняння. Вказані показники можуть також входити в протиріччя з іншими — адекватності та інформативності. Причому таке протиріччя може мати місце навіть у повному факторному експерименті. Наприклад, включення нових, формально значимих членів у модель, веде до зниження її інформативності. Або модель вже адекватна, але є ще формально значимі регресори, які в неї не ввійшли. 3.4. Аналіз якості моделіSatius est bene ignorabe, quam malt didicisse[12] Вы же знаете этих непосвященных, которые с трудом различают крупную дипломатическую победу и тяжкое дипломатическое поражение. Кейт Лаумер “Мирный посредник” Для прийняття рішення про межі використання побудованої моделі необхідно провести аналіз її властивостей. Із вищевказаного випливає, що оцінка якості моделі по одній чи двом характеристикам недостатня. Необхідна комплексна оцінка, яка дозволяє оцінити статистичні та споживацькі властивості моделі в повному обсягу. Основними показниками якості моделі є: 1. Інформативність. 2. Адекватність. 3. Стійкість (коефіцієнтів регресії та структури моделі). 4. Описуючі властивості моделі. 5. Прогностичні властивості моделі. 6. Відображення структури зв`язків між факторами та відгуком. Обов`язково необхідно перевіряти інформативність, адекватність та стійкість. Бажано также аналізувати прогностичні властивості моделі. В нижче приведеній таблиці дані розрахункові формули та назви дисперсій, які в подальшому використовуються при аналізі якості моделі. Таблиця 3.1 - Дисперсії, що використовуються в регресійному аналізі
де N - число експериментів; k — число членів моделі; n - число дублюючих дослідів в кожному експерименті; Yij — значення відгуку в i-ому експерименті при j-ому дублі; — середнє значення по дублюючим дослідам i-ому експерименті; — значення відгуку, розраховане для i-ого експерименту по моделі; — загальне середнє. Інформативність Найбільш часто оцінкою інформативності служить величина множинного коефіцієнта кореляції R (коефіцієнт кореляції між експериментальним значенням відгуку та значенням відгуку, розрахованим по моделі). Чим ближче він до одиниці, тим інформативність моделі вище. Величина R2 показує долю загальної суми квадратів, що пояснюється моделлю R2 = S2ост / S2 (3.20) Його (R) значення повинно бути як можна ближче до одиниці. Але це тільки необхідна, але не достатня умова. Необхідно перевірити значимість коефіцієнта множинної кореляції по критерію Фішера FR = S2R/ S2ост > Fa,VR,Vост, (3.21) де VR, Vост степені свободи для дисперсії, що пояснюється моделлю та залишкової дисперсії відповідно. Якщо розраховане значення більше табличного з заданим рівнем значимості, то модель інформативна. Така перевірка є якісною (типу так або ні). Для того, щоб оцінити рівень інформативності кількісно необхідно скористатися критерієм Бокса-Веца. Для якісної моделі необхідно, щоб значення параметра критерія Бокса-Веца було не нижче чим 2 — 3. ??визначається з наступного рівняння: F0 @ (1 + ) Fa,v0,vост, где v0 = vR (1 + )2/(1 + 22) (3.22) При неможливості точно визначити по цій формулі, пам`ятайте, що значенню =3 відповідає ситуація, коли Fрасч »10Fтабл. Адекватність В математичному моделюванні під адекватністю розуміється відповідність моделі об`єкту, який вона описує, по сукупності певних умов. В регресійному аналізі у вузькому значенні перевірка адекватності зводиться до перевірки по критерію Фішера належності дисперсії відтворюваності та залишкової дисперсії до однієї генеральної сукупності. При позитивній відповіді (F-табличне меньше F-розрахованого) різниця дисперсій статистично незначима і модель вважається адекватною. Звертаємо вашу увагу на деякі важливі моменти. Ця перевірка є формальною, тому кінцеве рішення об адекватності моделі необхідно приймати виходячи з придатності моделі для практичного використання по всій сукупності показників. Можлива така ситуація, що модель формально неадекватна, але практично вона задовольняє дослідника (адекватно описує процес): структура зв`язків, точність опису та прогнозування тощо. При наявності дублюючих дослідів адекватність перевіряється по критерію Фішера: F = S2восп/ S2ост< Fтабл, a,(n-1)N,N-k. (3.23) В тому випадку, коли повторні досліди відсутні, модель вважається адекватною, якщо виконується умова[14]: S2/ S2ост>(N - k)/(N-1)(1+((k-1)(N-k))Fa,k-1,N-k). (3.24) Потрібно мати на увазі, що ця формула не може дати інформацію для прийняття рішення про припинення включення регресорів в модель і її адекватності. Бажано провести смисловий аналіз і можливо виконати наступні дії. 1. Проаналізувати діаграму впливу регрессорів (підрозділ “Аналіз структури зв`язків”). 2. Проаналізувати характер зміни значень S2ост від включення нових членів в модель. Якщо залишкова дисперсія починає збільшуватися, то введення нових членів необхідно припинити. 3. Проаналізувати динаміку зміни FR при включенні нових членів і зупинитися на моделі з його максимальним значенням. Після того як модель стала адекватною по F-критерію, не слід в неї включати додаткові члени, оскільки вони не несуть ніякого смислового навантаження і це приводить до зниження або навіть втрати інформативності (зменьшується FR). Результати експерименту і розраховані по адекватній моделі значення розрізнити статистично неможливо. Розраховане значення F-критерію завжди повинно бути більше одиниці, тобто це відношення більшої дисперсії до меншої. В тому випадку, якщо воно виявилося менше одиниці, його необхідно перерахувати. При цьому потрібно не забувати, що для табличного значення F-критерію числа степенів свободи V1 і V2 поміняються місцями і само значення буде іншим. Стійкість Чим більше рахуєш, тим більше заплутуєшся. Тамільська приказка Краще ніякої поради ніж погана. Норвежська приказка В регресійному аналізі стійкість має два значення: 1) стійкість структури рівняння регресії; 2) стійкість оцінок коефіцієнтів регресії. Як перша так і друга стійкість залежать від властивостей матриці експерименту та алгоритмів, по яким отримується структура та коефіцієнти моделі. Безпосередньо стійкість в ПЗ ПРІАМ не перевіряється, оскільки це вимагає проведення обчислювального експерименту, який вимагає ресурсів на порядок більше, ніж сама побудова моделі. Разом з тим виконується розрахунок ряду параметрів, які дозволяють з певністю робити висновки про стійкість структури та коефіцієнтів. При аналізі стійкості позглядається таблиці мультиколлінеарності і число обумовленості. Таблиця мультиколлінеарності складається з наступних стовбчиків: імена регрессорів, що увійшли в модель; максимальний по абсолютній величині коефіцієнт парної кореляції, який даний регресор (його стовбчик) має з іншими регресорами, що складають модель; ім`я цього регресора; коефіцієнт кореляції з відгуком. Ця таблиця дозволяє проаналізувати стійкість структури рівняння регресії. Бажано, щоб виконувалися наступні умови: - максимальний коефіцієнт парної кореляції між регресорами не повинен перевищувати по абсолютному значенню 0,3 — 0,4; - коефіцієнт парної кореляції з відгуком по абсолютній величині повинен бути суттєво більший ніж максимальний коефіцієнт кореляції з іншим регресором. При виконанні цих умов можна бути впевненим в стійкості структури рівняння регресії. Якщо друга умова не виконується тільки для окремих регресорів, то виникає сумнів про правильність входження в модель саме цих членів. Розглянемо як приклад табл. 3.2. З неї добре видно, що регрессор х8 має коефіцієнт кореляції з регресором х2 по абсолютній величині більший, ніж його коефіцієнт кореляції з відгуком (0,41 проти 0,23). В цій ситуації необхідність введення його в модель сумнівна. Таблиця 3.2
Число обумовленості (cond) розраховується як відношення норм прямої і оберненої матриць нормальних рівнянь[15] і показує, в скільки разів може збільшитися помилка в коефіцієнтах при наявності помилки в вихідній матриці. По величині цього числа можно робити висновок про стійкість оцінок коефіцієнтів регресії. Теоретично найкращим значенням є cond=1 (досягається тільки доя ортогональної і одночасно нормованої матриці). При величині cond в десятки тисяч матриця практично є виродженою. Якщо cond має значення в сотні або тисячі, то слід турбуватися про стійкість оцінок. Потрібно мати на увазі, що в такій ситуації статистичні оцінки закорельовані і не несуть ніякої корисної інформації. Елементи теорії систем масового обслуговування [16] Випадкові процеси Стохастичний процес — це функція, яка приймає випадкові значення. Стохастичні процеси виникають в випадкових експериментах, результати яких можна описати в будь-який момент часу значенням випадкової величини. Стаціонарним випадковим процесом называється такий процес, в якому розподіл випадкових величин не залежить від інтервалу часу. Математичне сподівання в такому процесі також не залежить від часу, а кореляційна функція залежить тільки від інтервалу часу, а не від точки відліку. Потік подій — послідовність подій, які відбуваються у випадкові моменти часу. [1] Назви обґрунтована (consistent), ефективна (efficient) і достатня (sufficient) оцінки введені Р.А. Фішером в 1925 г. Сьогодні, як правило, використовують перші дві властивості. [2] Таку формулу звичайно використовують у тих випадках, коли ми маємо справу зі згрупованими даними, наприклад, інтервали доходу (від і до) та доля населення з такими доходами. Тоді середина інтервалу вважається середнім і ми можемо по вказаній формулі виконувати розрахунок середнього для всієї вибірки. [3] Ця властивість медіани може використовуватись, наприклад, для вибору місця зупинки міського транспорту, бензоколонок тощо. [4] В зв`язку з цією властивістю, медіану використовують замість середнього в тих випадках, коли крайні значення сильно відрізняються від інших. [5]Відоме явище, коли при інфляції бідні стають біднішими, а багаті ще багатшими, з точки зору статистики є лише властивістю дисперсії. [6] Приведення до безглуздя. [7] Нема такого закону, який задовольняв би усіх [8] Ndiag – діагональна матриця, головна діагональ якої взята з N; Nsqr матриця, кожний елемент якої є квадратом відповідного елементу із N [9] Шуп Т. Решение инженерных задач на ЭВМ. Практическое руководство. –М.: Мир, 1982. –238с. [10]В літературі можна зустріти рекомендації про логарифмування відгуку в таких ситуаціях. Дійсно, в такому випадку, дисперсії, як правило, стають однорідними. Але всі отримані оцінки будуть відноситись до логарифмованому відгуку, тоді як для вихідного нічого не зміниться. [11] Опубліковані Чебишевим в 1853г. Використовуються при по побудові багаточленів і раціональних функцій, які апроксимують явно задані функції, при наближенні диференційних та інтегральних рівнянь, при прискоренні збіжності лінійних ітераційних процесів тощо. [12] Краще зовсім нічого не знати, чим знати погано. [13] Вперше зустрічається в підразділі “Аналіз однородності дисперсій”. [14] Иванов Г.А.,Турбан А.Ф. Статистические методы восстановления истинной зависимости по экспериментальным данным.— К.: Знание.— 1986.— 22 с. [15] Або як відношення максимального власного числа до мінімального для матриці лівої частини системи нормальних рівнянь. [16] За кордоном має назву “теорія черг” або “теорія очікування”. З повагою ІЦ "KURSOVIKS"! |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||




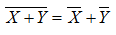 .
.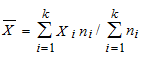 .
.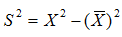 .
.



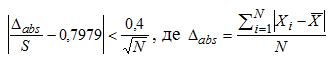 ,
,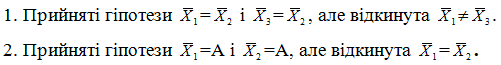
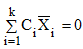 , де ci – певні константи, на яких накладається умова
, де ci – певні константи, на яких накладається умова 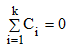 .
.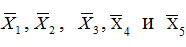 . Припустимо, що ми вважаємо, що ці вибірки належать до двох різних генеральних сукупностей, середні значення в яких
. Припустимо, що ми вважаємо, що ці вибірки належать до двох різних генеральних сукупностей, середні значення в яких 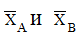 відповідно. Тоді нульова гіпотеза може бути сформульована у вигляді H0:
відповідно. Тоді нульова гіпотеза може бути сформульована у вигляді H0: 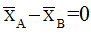 . При цьому в залежності від складу вибірок, із яких можуть складатися групи А і В можливі наступні варіанти цієї гіпотези.
. При цьому в залежності від складу вибірок, із яких можуть складатися групи А і В можливі наступні варіанти цієї гіпотези.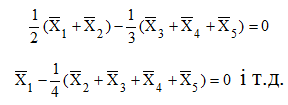
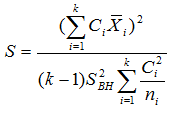 (3.13)
(3.13)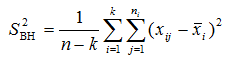 , а де
, а де  , k – число вибірок, ni – кількість елементів кожної вибірки,
, k – число вибірок, ni – кількість елементів кожної вибірки, 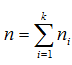 – загальна кількість спостережень. Якщо розраховане значення S буде більше критичного значення Fk-1,n-k,a, то гіпотеза про рівність середніх відповідних вибірок, чи груп вибірок відкидається.
– загальна кількість спостережень. Якщо розраховане значення S буде більше критичного значення Fk-1,n-k,a, то гіпотеза про рівність середніх відповідних вибірок, чи груп вибірок відкидається.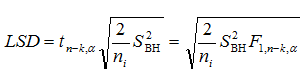 (3.14)
(3.14)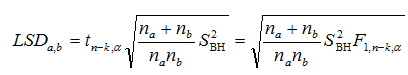 ,
, ).
). ).
). ).
). ).
). .
.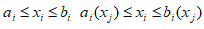 .
.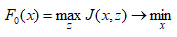 . Тобто виконується мінімізація по X для найгіршого можливого результату, до якого приводить Z.
. Тобто виконується мінімізація по X для найгіршого можливого результату, до якого приводить Z.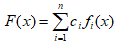
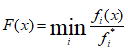 . Задача зводиться до пошуку максимуму F(x).
. Задача зводиться до пошуку максимуму F(x).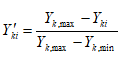 (4.3)
(4.3)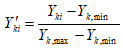 (4.4)
(4.4)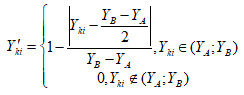 (4.5)
(4.5)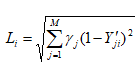 (4.6)
(4.6)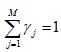 .
.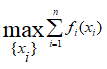 при умовах
при умовах 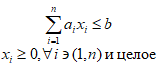
 . Розв’язок знаходиться точно так, тільки змінюється знак (сума на добуток) в рекурентній формулі.
. Розв’язок знаходиться точно так, тільки змінюється знак (сума на добуток) в рекурентній формулі.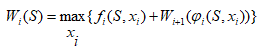 . Цьому виграшу відповідають умови оптимального управління xi(S) на i-му кроці.
. Цьому виграшу відповідають умови оптимального управління xi(S) на i-му кроці.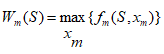 . Знаходиться xm(S), для яких виграш досягає максимуму..
. Знаходиться xm(S), для яких виграш досягає максимуму..
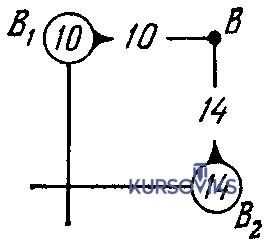
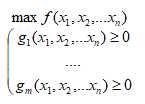

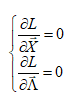
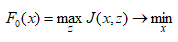 . Тобто виконується мінімізація по X для найгіршого можливого результату, до якого приводить Z.
. Тобто виконується мінімізація по X для найгіршого можливого результату, до якого приводить Z.
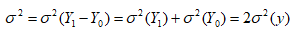 . При перетворення тут і далі використовуються властивості дисперсії.
. При перетворення тут і далі використовуються властивості дисперсії.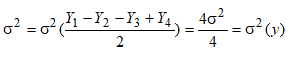
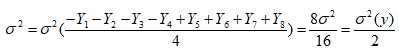 .
.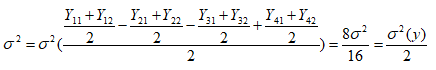

")
 та Франції
та Франції 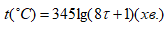 . Вказані формули приводяться в відповідних документах по пожежній справі. Необхідно виконати наступні дії.
. Вказані формули приводяться в відповідних документах по пожежній справі. Необхідно виконати наступні дії.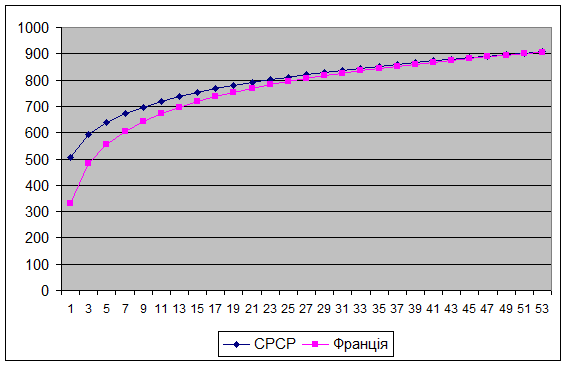




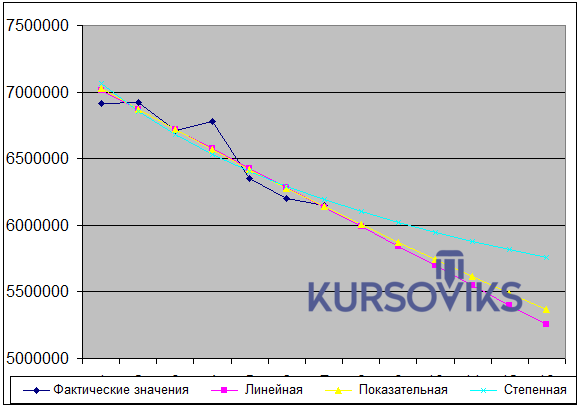


 (2.2)
(2.2) (2.3)
(2.3)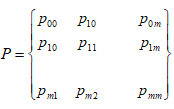 (2.4)
(2.4)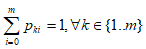 (2.5)
(2.5)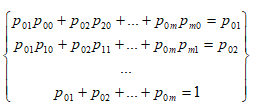 (2.7)
(2.7)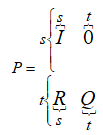 (2.8)
(2.8)
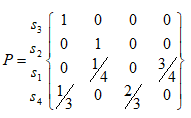
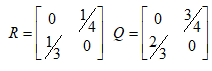 .
.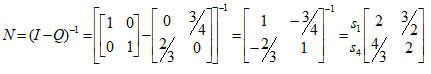
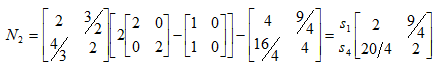
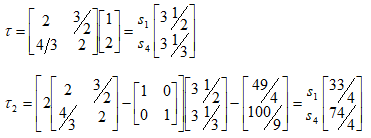

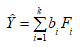


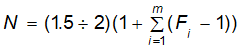 , (1.2)
, (1.2)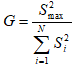 , (3.1)
, (3.1)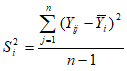 , (3.2)
, (3.2)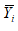 — середнє значення відгуку в i-тому досліді; Yij — значення відгуку в i-ому досліді при j-ому повторенні.
— середнє значення відгуку в i-тому досліді; Yij — значення відгуку в i-ому досліді при j-ому повторенні. . (3.3)
. (3.3)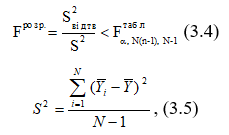
 — загальне середнє, тобто середнє всіх середніх по стовпчику.
— загальне середнє, тобто середнє всіх середніх по стовпчику.
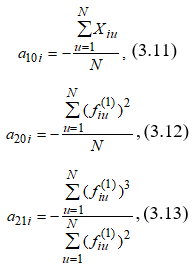
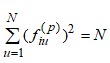 , " p и " i О (1, m) (3.14)
, " p и " i О (1, m) (3.14)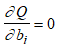 , підставивши замість Yi значення виразу (6.10) отримаємо систему рівнянь наступного виду (в матричній формі запису):
, підставивши замість Yi значення виразу (6.10) отримаємо систему рівнянь наступного виду (в матричній формі запису):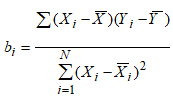 . (3.17)
. (3.17)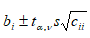 , (3.18)
, (3.18)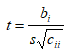 . (3.19)
. (3.19)